
Web siteleri, tarayıcılarla konuşmayı öğrendi, ardından arama motorlarıyla iletişim kurmaya başladı. Cloudflare, artık web sitelerinin IA ajanslarıyla konuşmayı öğrenmesi gerektiğini düşünüyor ve bu konuda yardımcı olacak bir araç sunuyor. Bu, iddialı bir girişim ancak çözümden daha fazla soru ortaya çıkarıyor.
Öne Çıkanlar:
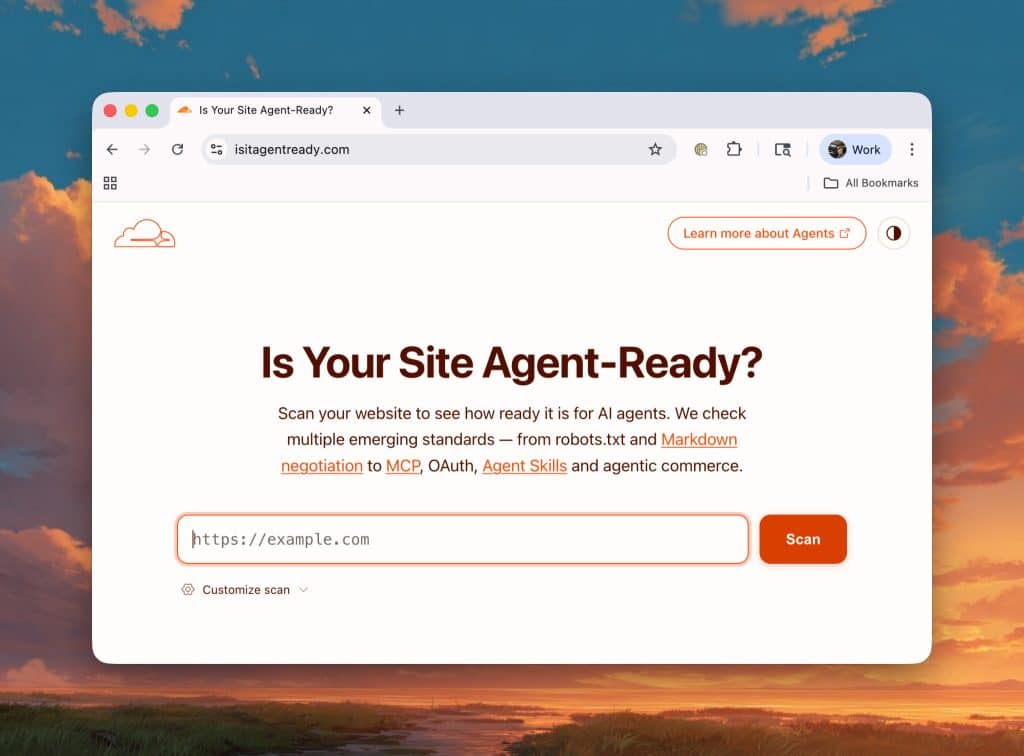
- Cloudflare, web sitelerinin IA ajanslarıyla uyumluluğunu dört boyutta değerlendiren ücretsiz bir araç olan isitagentready.com'u başlattı: keşfedilebilirlik, içerik, erişim kontrolü ve yetenekler.
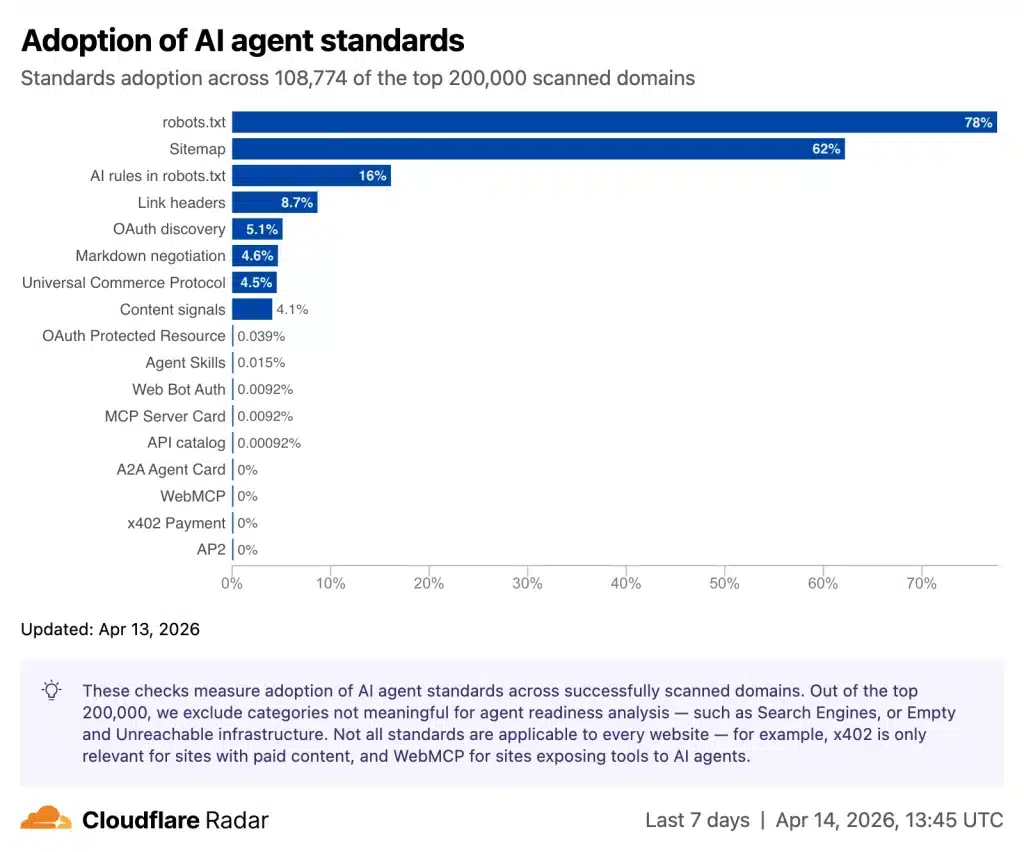
- Web, henüz hazır değil: Analiz edilen 200.000 web sitesinin sadece %4'ü IA kullanımı için tercihlerini bildiriyor ve 15'ten az site, MCP Sunucu Kartları veya API Katalogları gibi en son standartları benimsedi.
- Girişim, inşası devam eden bir standart ekosistemine dayanıyor, bu da erken benimseyenleri parçalanma veya hızlı eskime riskine maruz bırakıyor.
- Cloudflare, hem skoru belirleyen hem de iyileştirmek için çözümler sunan bir konumda, bu durum sorgulanmayı gerektiriyor.
Gerçek Bir Sorun İçin Notlandırma Aracı
Cloudflare'ın başlangıç noktası sağlam. Bir IA ajansı, bir web sitesine erişip dokümantasyon okumak, ürün satın almak veya bir API ile etkileşimde bulunmak istediğinde, insanlara yönelik tasarlanmış bir altyapıyla karşılaşıyor: yoğun HTML, formlar, oturumlar, captcha'lar. Sonuç olarak, yavaş, token açısından maliyetli ve genellikle hatalı ajanslar ortaya çıkıyor.
Cloudflare, en çok ziyaret edilen 200.000 alan adını tarayarak sorunun boyutunu ölçtü ve yönlendirmeleri, reklam sunucularını ve tünel hizmetlerini filtreleyerek, ajansların makul bir şekilde etkileşimde bulunabileceği sitelere odaklandı.
Sonuç çarpıcı: Sitelerin %78'inin bir robots.txt dosyası var, ancak bunların neredeyse tamamı geleneksel arama motoru tarayıcıları için yazılmış, ajanslar için değil. Sadece %3,9'u, talep edildiğinde Markdown formatında içerik sunuyor. Ve MCP Sunucu Kartları gibi yeni standartlar, veri kümesinin tamamında 15'ten az sitede mevcut.
Cloudflare tarafından tanıtılan isitagentready.com çözümü, dört eksen etrafında yapılandırılmış bir puan sunuyor.
- Keşfedilebilirlik (discoverability),
robots.txt,sitemap.xmlve Link Headers'ın varlığını ve kalitesini kontrol ediyor. - İçerik (content), sitenin bir ajansın talebine uygun temiz bir Markdown versiyonu sunup sunmadığını değerlendiriyor.
- Erişim Kontrolü (bot access control), sitenin IA'ların içeriğiyle ne yapabileceği konusunda net tercihler ifade edip etmediğine bakıyor.
- Son olarak, yetenekler, ajansların düzgün bir şekilde kimlik doğrulaması yapabilmesi için MCP Sunucu Kartları, API Katalogu veya OAuth keşfi gibi daha gelişmiş standartların varlığını test ediyor.
Henüz Gelişmekte Olan Standartlar ve Neredeyse Yok Denilecek Düzeyde Benimseme
Burada Cloudflare'ın heyecanı sınırlanmalı. Bu puanda öne çıkan standartların birçoğu ya IETF'de taslak aşamasında ya da genel kabul görme garantisi olmayan gayri resmi öneriler. API Katalogu (RFC 9727), MCP Sunucu Kartları veya Web Bot Auth, bazıları yayın tarihinde kesin RFC statüsüne ulaşmamış yeni standartlar.
Bu durum yalnızca Cloudflare'a özgü değil: bu, evrim aşamasındaki bir webin gerçeği. Ancak, bu durum Cloudflare'ın blog yazısında küçümsenen bir dürüstlük gerektiriyor. Bugün benimsenen bir standardın on sekiz ay içinde yeniden düzenleneceği veya terk edileceği düşünülürse, bu potansiyel olarak yeniden entegrasyon gerektiren bir iş yükü oluşturabilir. Büyük oyuncular, bu evrimleri takip edecek kaynaklara sahipken, daha küçük ekipler veya bağımsız geliştiriciler için durum böyle olmayabilir.
llms.txt örneği dikkat çekici. Eylül 2024'te önerilen, bir siteyi bir LLM'ye tanıtmak için standartlaştırılmış bu dosya, Cloudflare'ın puanında varsayılan olarak yer almıyor, yalnızca isteğe bağlı. Sebebi? Standart hala tartışma aşamasında. Bu, dikkatli bir karar ama aynı zamanda Cloudflare'ın hangi riskleri alması gerektiğini henüz bilmediğini gösteriyor.
Markdown İçeriği Müzakeresi: Ölçülen Gerçek Bir Kazanç
İnisiyatifin en somut yönlerinden biri ve muhtemelen en acil faydalı olanı, bir ajansın Accept: text/markdown başlığı gönderdiğinde bir sunucunun Markdown formatında yanıt verme yeteneğidir. Cloudflare, bir sayfayı okumak için gereken token sayısında %80'e kadar bir azalma ölçtüğünü iddia ediyor.
Bu rakamın bağlamı önemlidir. Teknik bir dokümantasyon sayfasının HTML'i genellikle çok fazladır: navigasyon, menüler, scriptler, iç içe geçmiş etiketler... bunların hepsi bir LLM için saf gürültü oluşturur. İyi yapılandırılmış bir Markdown dosyası, içeriğin ambalajsız özüdür. Doğrudan sonuç, ajanslar için API çağrılarının maliyetinin düşmesi, gecikmenin azalması ve ajansın kesintiye uğramadan tam bağlamı elde etme olasılığının artmasıdır.
Cloudflare, kendi dokümantasyon sitesini (developers.cloudflare.com) test ettiğini ve bir ajansı (Kimi-k2.5 OpenCode aracılığıyla) birkaç teknik siteye yönlendirdiğini açıklıyor. Sonuç: %31 daha az token tüketimi ve diğer optimize edilmemiş sitelere göre %66 daha hızlı doğru yanıtlar. Bu rakamlar, denetim edilmemiş iç test koşullarından kaynaklandığı için dikkatle ele alınmalıdır. Ancak büyüklük sırası, HTML'nin yapısal aşırılığı hakkında bilinenlerle tutarlıdır.
Cloudflare Docs'ta Teknik Uygulama: Pratik ve Tekrar Edilebilir
Yazının en öğretici kısmı, Cloudflare'ın kendi dokümantasyonunu nasıl yeniden yapılandırdığıdır. Yaklaşım ilginç çünkü gerçek bir sorunu aşar: Şubat 2026'da test edilen yedi araçtan yalnızca üçü (Claude Code, OpenCode ve Cursor) otomatik olarak Accept: text/markdown başlığını gönderiyor. Diğerleri için bir alternatif gereklidir.
Seçilen çözüm, iki Cloudflare kuralını birleştiriyor:
- Bir URL yeniden yazımı,
/r2/get-started/index.mdisteğini/r2/get-started/isteğine dönüştürüyor, - Ve yeniden yazılan bu isteklere otomatik olarak
Accept: text/markdownbaşlığını ekliyor.
Sonuç: Herhangi bir ajans, URL'ye /index.md ekleyerek herhangi bir sayfanın Markdown versiyonuna erişebilir, özel bir başlık yönetmeye gerek kalmadan.
Diğer bir dikkat çekici karar: tek bir dev llms.txt dosyası yerine (Cloudflare dokümantasyonu 5.000'den fazla sayfa içeriyor), her birinci seviye dizin kendi dosyasına sahip ve kök dosya bu alt dizinlere işaret ediyor. Bu, yazıda açıklanan grep döngüsünü önlüyor: çok uzun bir dosyayla karşılaşan bir ajans, ana hatları kaybetmeye başlar, anahtar kelimelerle arama yapar, çağrıları artırır ve yanıt kalitesini düşürür.
Granülarite de dikkatle ele alındı: Yaklaşık 450 sayfa yalnızca bağlantı listeleri (dizin sayfaları) llms.txt'dan hariç tutuldu, çünkü bunlar zaten bireysel olarak listelenen alt sayfalar için bir LLM'ye hiçbir anlamsal değer katmıyor.
Puan Veren ve Puan Hazırlığı Satan Bir Oyuncu
Cloudflare'ın konumu dikkatle incelenmeyi gerektiriyor. Şirket, ajans hazırlığı için referans puanını yayınlıyor, bu puanı URL Tarayıcısına entegre ediyor, her bir başarısızlık noktasını düzeltmek için hazır şablonlar sunuyor... ve bu düzeltmeleri uygulamak için ürünler (Workers, Rules, Access) satıyor. isitagentready.com kendisi de Cloudflare tarafından sunulmakta ve bir MCP sunucusu barındırmaktadır.
Bu, mutlaka sorunlu değil: Google, Lighthouse ve Core Web Vitals ile aynı şeyi yaptı ve performansın hem yargıcı hem de iyileştirmek için araçlar sağlayan bir sağlayıcı haline geldi (Google Cloud, Firebase vb. aracılığıyla). Ancak bu, puanın kriterlerinin, şirketin ticari çıkarları kadar, gerçek ajans ihtiyaçlarına göre de evrilebileceği anlamına geliyor. Tek bir şirket tarafından desteklenen bir standart, iyi niyetle bile olsa, yönlendirmeleri etkileyebilir.
Ayrıca, Cloudflare'ın aktif olarak ajans ödemeleriyle ilgili standartları (x402, Evrensel Ticaret Protokolü) teşvik etmesi dikkat çekici; bu standartların bazıları Coinbase gibi doğrudan ortakları içeriyor. Bu standartlar henüz puana dahil değil, ancak araçtaki varlığı zaten bir yönü işaret ediyor.
Geliştiricilerin Bugün Gerçekten Yapabileceği Şeyler
Bu çekincelere rağmen, birçok eylem net ve anında bir geri dönüş sağlıyor, standartların evriminden bağımsız:
- Talep üzerine Markdown sunmak teknik olarak basit, API tüketicileri için maliyetleri düşürüyor ve ajansların yanıt kalitesini artırıyor. Bu öncelik.
- IA ajansları için
robots.txt'ı düzenlemek (örneğinGPTBot,ClaudeBot,CCBotgibi tarayıcılar için yönergeler ekleyerek) iyi bir hijyen ve maliyetsizdir, erişim haklarını netleştirir. - Birçok içeriğe sahip siteler için
llms.txt'ı bölüm bazında yapılandırmak, hem ajanslar hem de bir sitenin mimarisini hızlıca anlamak isteyen insanlar için iyi bir belgelendirme uygulamasıdır.
Öte yandan, henüz kamuya açık bir API'si veya net bir ajans kullanım durumu olmayan bir site için MCP Sunucu Kartları veya API Katalogları uygulamak, ziyaretçileri olmadan bir bekleme odası inşa etmekle eşdeğerdir.
Piyasa Göstergesi Olarak Benimseme, Zorunluluk Olarak Değil
Cloudflare'ın girişiminin gerçek değeri, belki de Radar veri kümesinde yatıyor: En çok ziyaret edilen 200.000 sitenin her bir standardın benimsenmesini haftalık olarak takip eden bir veri seti, alan adı kategorilerine göre segmentlenmiş. Bu tür veriler, standartların gerçekten kazanç sağlayıp sağlamadığını veya çoğu sitenin, ajansların onlara uyum sağlamasını bekleyerek pasif kaldığını ölçmeye olanak tanıyacak; bu, zaten otuz yıldır HTML'ye uyum sağladıkları gibi.
Bu sorunun yanıtı, site yayıncıları ile ajans geliştiricileri arasındaki güç dinamiği hakkında çok şey söyleyecek. En popüler ajanslar, yeterince sağlam HTML ayrıştırma yetenekleri kazandıklarında, sitelerin uyum sağlaması üzerindeki baskı azalacak. Aksine, optimize edilmemiş HTML tüketiminin maliyetleri ve süreleri, uyum sağlayan siteler için ölçülebilir bir rekabet avantajı haline gelirse, benimseme doğal olarak artacaktır.




































Yorumlar
(6 Yorum)