
Bir web sitesinde tarama yaptığınızda, ilk refleks genellikle aynıdır: HTTP kodları listesinin içine dalmak, 404 hatalarını filtrelemek, kopya başlıkları takip etmek ve her sayfanın bir H1'e sahip olup olmadığını kontrol etmek. Bu analizler zorunludur. Ciddi bir teknik denetimin temelini oluştururlar ve kimse bunlardan vazgeçmemelidir.
Ancak bir taramanın zenginliği bununla sınırlı değildir. Klasik göstergelerin arkasında, sitenin gerçek sağlığına dair değerli bir ışık tutan daha az yaygın analizler gizlidir. Bu makalede bunlardan üç tanesi sunulmaktadır. Alışılmış kontrollerin yerini almak için değil, belki de henüz kullanmadığınız analiz açılarının eklenmesi için.
Bu makaledeki görsel örnekler, açık kaynaklı ve kendi kendine barındırılabilen bir SEO tarayıcısı olan Scouter'dan alınmıştır. Ancak burada açıklanan ilkeler, kullandığınız araç ne olursa olsun geçerlidir.
Konunun özüne girmeden önce, bir ön koşul vardır.
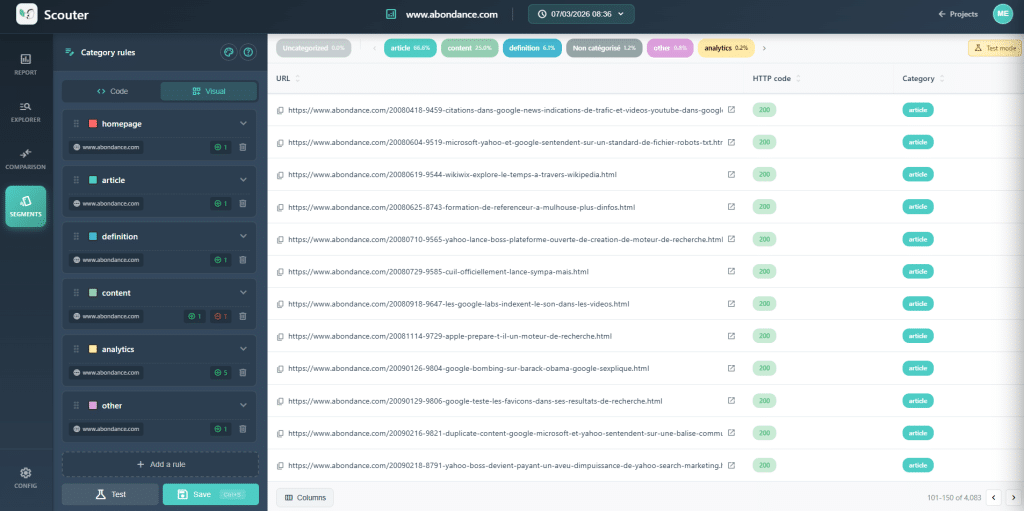
Herhangi Bir Analizden Önce: URL'lerinizi Kategorize Edin
Bu, ham bir taramayı bir teşhis aracına dönüştüren harekettir. Herhangi bir şeyi analiz etmeden önce, ilk adım URL'lerinizi teknik şablona göre gruplamaktır: ürün sayfaları, kategori sayfaları, blog yazıları, kurumsal sayfalar vb. Bu kesim olmadan, kör bir şekilde çalışıyorsunuz.
Neden Bu Zorunlu?
Somut bir örnek alalım. Taramanız, sitenin genelinde %30 oranında kopya H1 olduğunu gösteriyor. Bu rakam korkutucu. Ancak mevcut haliyle, sorunun nedenine dair hiçbir şey söylemiyor.
Şimdi, bu veriyi kategoriye göre ayırın. Kopyanın büyük ölçüde ürün sayfalarına odaklandığını keşfedeceksiniz. Hipotez netleşiyor: varyant (renk, boyut) aynı H1'i üretiyor çünkü varyant başlıkta yer almıyor. Öneri de açıktır: ürün H1'inin oluşturulma kuralını değiştirerek varyantın niteliğini (örneğin ürünün rengi) eklemek.
Makale şablonunda, aynı semptom tamamen farklı bir nedene sahip olabilir: şablonun kötü işaretlenmesi, sabit kodlanmış bir H1, yanlış yapılandırılmış bir editoryal alan. Öneri de farklı olacaktır.
Akılda Tutulması Gereken Mantık: Anomalinin Farkına Var → Şablona Göre Ayır → Örnekleri Gözlemle → Deseni Anla → Hedefe Yönelik Bir Öneri Oluştur.
Bu kategorize etme süreci, ardından gelen tüm analizlere anlam katmaktadır. Verilerinize uyguladığınız bir filtre olarak düşünün, genel bir gözlemden ince bir anlayışa geçiş yapmanızı sağlar.
1. Tarama Derinliği: Mimarinizi Hızla Teşhis Edin
Bir tarama sırasında elde edilen veriler arasında, sayfaların derinlik seviyesi muhtemelen en anlamlı olanıdır. Birçok kişi bunu göz ardı eder, önemli sayfaların "çok derin olmadığını" kontrol etmekle yetinir. Bu, esas olanı kaçırmaktır.
Ne Konuşuyoruz?
Bir sayfanın derinlik seviyesi, ana sayfadan ona erişmek için takip edilmesi gereken minimum bağlantı sayısını ifade eder. Bu en kısa yoldur, herhangi bir yol değil. Genellikle "tıklama" terimi kullanılarak basitleştirilir, ancak önemli olan bağlantılardır. Ana sayfa 0. seviyededir, doğrudan bağladığı sayfalar 1. seviyededir ve bu şekilde devam eder.
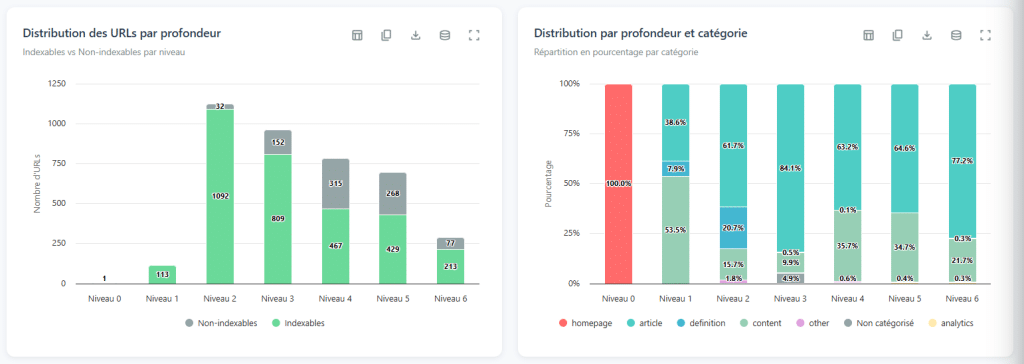
Derinlik Eğrisini Okuma
Bu analizdeki ilgi, ham sayılarda değil, dağılım eğrisinin şeklinin incelenmesindedir. Sadece ona bakarak, büyük yapısal sorunları teşhis edebilirsiniz.
Düz bir eğri, onlarca seviyeye yayıldığında (her katmanda az sayıda sayfa ile birlikte): bu, neredeyse kesin bir doğrusal sayfalama belirtisidir. Site, yalnızca bir sayfadan diğerine geçmeye izin verir; sayfa 1, sayfa 2, sayfa 3… Tarayıcı, dizinin sonundaki içeriklere ulaşmak için her aşamayı geçmek zorundadır. Sonuç: en derin sayfalar neredeyse erişilemez hale gelir.
İki tepeli bir eğri (yükselir, düşer, sonra tekrar yükselir): bu, neredeyse yetim bir bölüm sinyalidir. İlk tepe, iyi bir şekilde bağlantılı sitenin kalbini temsil eder. İkinci tepe, yalnızca derinlikteki birkaç bağlantıyla diğerine bağlı bir dizi sayfayı temsil eder. Bu nadir bağlantıları keserseniz, sitenin bu kısmı tamamen izole olur. Sonuç: çok az erişilebilirlik, çok az aktarılan otorite.
Çok fazla derinlik, çok az sayfa için (örneğin, beş seviye ve yalnızca elli sayfa): burada iç bağlantıda bir verimlilik sorunu vardır. Bu sayfaların erişilebilir olmasını sağlamak için çok daha az tıklama ile ulaşılabilir olmalıdır.
"3 Tıklama" Kuralını Unutun
Meşhur "her şey 3 tıklamada erişilebilir olmalıdır" kuralı, kalıcı bir efsanedir. Amazon veya herhangi bir büyük ölçekli siteye uygulamayı hayal edin: bu, basitçe imkansızdır. Belirli bir sayıya bağlı kalmak yerine, oranlar üzerinden düşünmek daha faydalıdır.
Derinliğinizin tutarlı olup olmadığını değerlendirmek için basit bir teorik temel alın. Ana sayfanın (seviye 0) yaklaşık 100 sayfa keşfettiğini varsayın. Daha sonra, her yeni sayfanın ortalama 10 sayfa daha keşfettiğini düşünün. Sonuç: seviye 1'de yaklaşık 100 sayfa, seviye 2'de 1.000 sayfa, seviye 3'te 10.000 sayfa.
Amacınız bu modele tam olarak uymak değil, gerçek derinliğinizi bu teorik temel ile karşılaştırmaktır. Eğer sitenizin 500 sayfası varsa ve zaten 5 derinlik seviyeniz varsa, bağlantıyı araştırmalısınız çünkü bu sayfaları teorik olarak yalnızca 2 derinlik seviyesi ile kapsayabilirsiniz.
2. Yakın Kopya: Görünmeyen Kopyalama
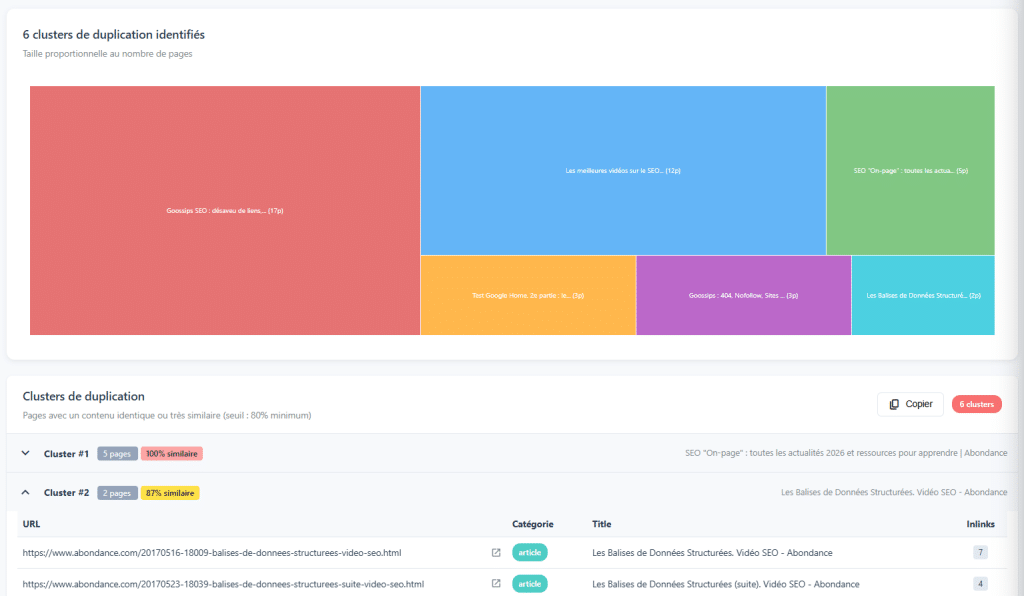
İçerik kopyalaması söz konusu olduğunda, herkes DUST'u (Duplicate URL, Same Text) bilir: tam olarak aynı içeriği sunan iki farklı URL. Bunu tespit etmek kolaydır ve genellikle düzeltmek basittir. Ancak daha sinsice bir kopyalama biçimi vardır: yakın kopya.
Birbirine Aşırı Benzeyen Sayfalar
Yakın kopya, içeriği tam olarak aynı olmasa da çok benzer olan sayfaları ifade eder. Bazı kelimelerin değişmesi, bir paragrafın eklenmesi veya çıkarılması, hafif bir yeniden ifade… ancak temelde benzer bir içerik. Tespit algoritmaları (birçok tarayıcı tarafından kullanılan Simhash gibi) bu benzerlikleri içerik izlerini karşılaştırarak tanımlar.
Bu sayfalar gerçek bir sorun teşkil eder. Otoriteyi birden fazla URL arasında dağıtırlar, tek bir yerde yoğunlaştırmak yerine. Kendilerini konumlandırmada birbirlerini tüketirler. Ve Google'a düşük değerli içerik sinyali gönderirler. Bazı durumlarda, doğru karar bu içerikleri daha zengin ve daha alakalı tek bir sayfada birleştirmektir.
Yanlış Pozitiflere Dikkat Edin
Bu önemli bir dikkat noktasıdır: Herhangi bir içerik benzerliği mutlaka bir sorun değildir.
Birçok dildeki bir siteyi yönetiyorsanız ve en-GB ve en-US sürümleri varsa, bu sayfaların neredeyse aynı olması tamamen normaldir. Farklı pazarlara hitap ediyorlar. Aynı mantık, coğrafi olarak yerelleştirilmiş sayfalar için de geçerlidir: "Paris'teki tesisatçı" ve "Lyon'daki tesisatçı" genellikle küçük varyasyonlarla aynı şablonu paylaşır ve bu da amaçlıdır. Yakın kopya, araştırılması gereken bir sinyal, otomatik bir hüküm değildir. Gerçek bir sorun mu yoksa sitenin bağlamına bağlı bir yanlış pozitif mi olduğunu belirleyen, arka plandaki manuel analizdir.
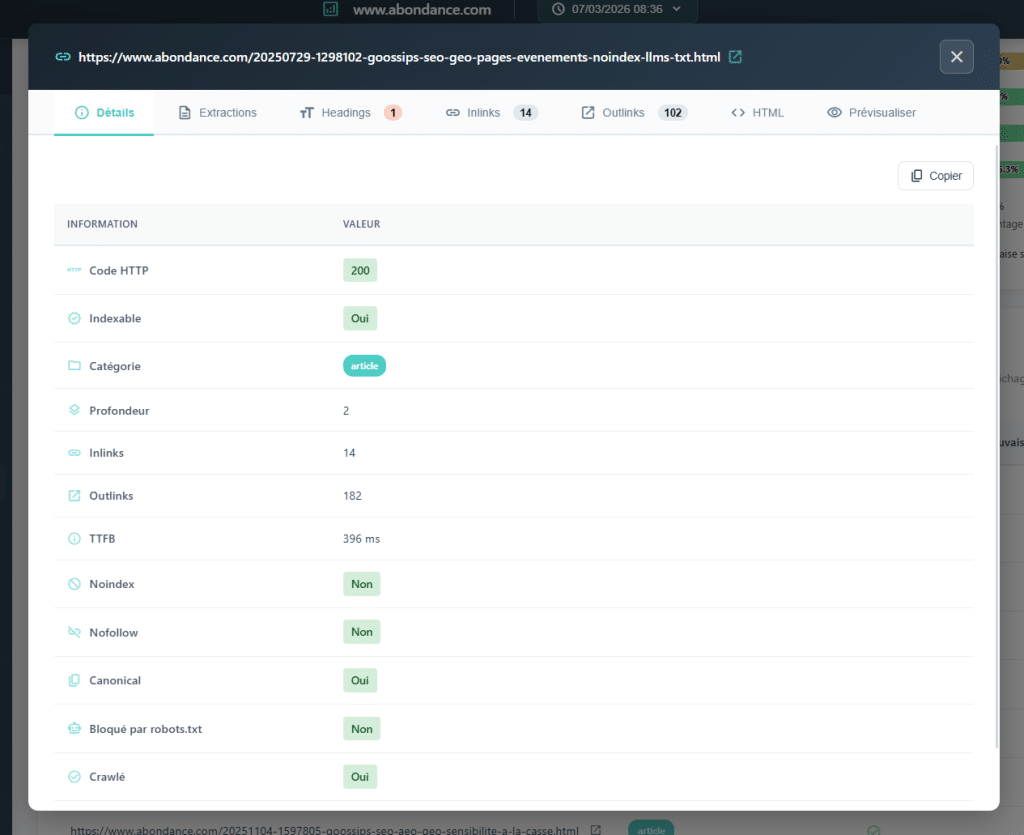
3. Hn Yapısı: H2, H3, H4'leriniz Gerçekten Düzenli mi?
Bir sitenin işaretlemesini denetlerken, refleks H1'i kontrol etmektir: mevcut mı? Eşsiz mi? İlgili mi? Bu iyi. Ancak bir sayfanın başlık yapısı sadece H1 ile sınırlı değildir. İçeriği düzenleyen ve motorların içeriği anlamasına yardımcı olan tüm hiyerarşidir (H1'den H6'ya kadar).
Gözle Görünmeyen Sorunlar
Bir tarama ölçeğinde Hn yapısını analiz etmek, yalnızca H1'i kontrol etmekle ortaya çıkmayan sistemik anormallikleri tespit etmeyi sağlar.
Seviyelerde atlamalar: bir sayfanın doğrudan H1'den H3'e geçmesi, H2 ara katmanı olmadan. Bu, belgenin hiyerarşik mantığında bir kopmadır. H1'lerin eksik olduğu, H2'lerin mevcut olduğu, sıkça karşılaşılan yapısal tutarsızlıklar. Tamamen düzensiz yapılar, kötü tasarlanmış bir şablonun veya yöntem olmadan işaretlenmiş bir içeriğin işareti.
Ayrıca H2'nin büyük ölçüde kopyalanması, yalnızca H1'lere baktığınızda genellikle görünmeyen bir semptomdur. Bu, bir şablon sorunu ortaya çıkarabilir: bir sayfadan diğerine yeniden kullanılan bloklar (widget'lar, yan çubuk modülleri, H2 olarak işaretlenmiş altbilgiler…) her sayfanın başlık yapısını kirletir.
Neden Önemli?
Google, bir sayfanın tematik yapısını anlamak için Hn etiketlerini kullanır. Tutarlı bir hiyerarşi, motorların ele alınan ana ve yan konuları tanımlamasına yardımcı olur. SEO'nun ötesinde, bu aynı zamanda erişilebilirlik meselesidir: ekran okuyucuları, bu hiyerarşiyi içerikte gezinmek için kullanır.
Bu analizdeki en büyük fayda, şablon hatalarını işaret etmesidir. Yüzlerce sayfada tekrarlanan bir Hn yapısı sorunu, genellikle düzeltilecek tek bir şablon sorunudur ve büyük bir etki yaratır.
Özetle
Bu üç analiz, teknik bir denetimin klasik kontrollerinin yerini almaz. Onları tamamlar. Bir kez ustalaştığınızda, gözlem açılarınızı genişleten bir dizi perspektif sunar.
Unutulmaması gereken en önemli nokta, bu üç örneği aşan bir gerçektir: bir tarama, bir amaç değil, bir teşhis aracıdır. Ham veriler, yorum olmadan hiçbir şey ifade etmez. Teknik bir denetimin gerçek değeri, desenleri okumak, nedenleri anlamak ve uygulanabilir önerilerde bulunma yeteneğidir. Ve her şey, analizden önce kategorize etme alışkanlığı ile başlar.
Bu makaledeki görseller, Scouter, açık kaynaklı ve kendi kendine barındırılabilen bir SEO tarayıcısı ile oluşturulmuştur. lokoe.fr/crawler-seo-scouter adresinde mevcuttur.




































Yorumlar
(8 Yorum)