
Lorsque vous effectuez un scan sur un site web, le premier réflexe est généralement le même : plonger dans la liste des codes HTTP, filtrer les erreurs 404, suivre les titres en double et vérifier si chaque page a un H1. Ces analyses sont indispensables. Elles constituent la base d'un audit technique sérieux et personne ne devrait s'en passer.
Cependant, la richesse d'un scan ne se limite pas à cela. Derrière les indicateurs classiques se cachent des analyses moins courantes qui éclairent la véritable santé du site. Cet article en présente trois. Non pas pour remplacer les contrôles habituels, mais peut-être pour ajouter des angles d'analyse que vous n'avez pas encore utilisés.
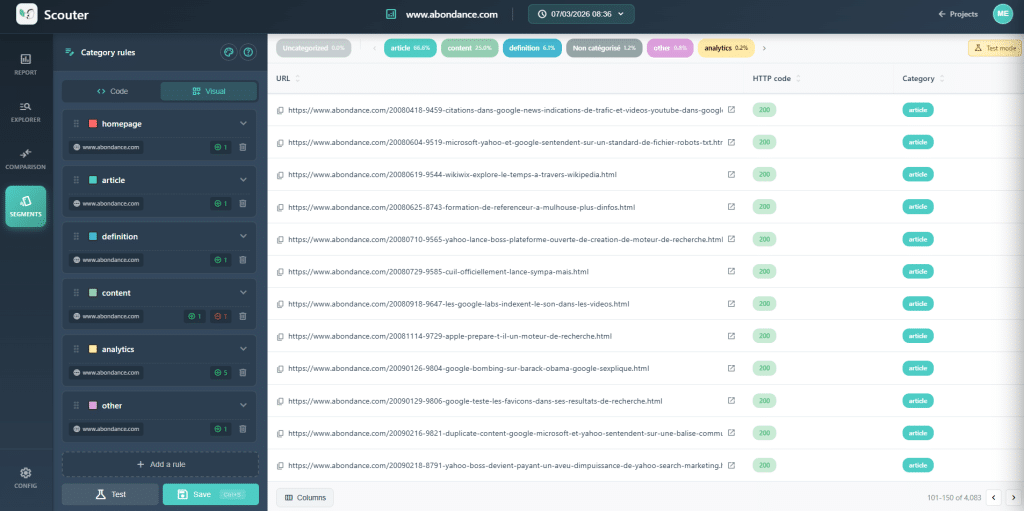
Les exemples visuels de cet article proviennent de Scouter, un outil de scan SEO open source et auto-hébergé. Cependant, les principes décrits ici sont valables quel que soit l'outil que vous utilisez.
Avant d'entrer dans le vif du sujet, il y a une condition préalable.
Avant Toute Analyse : Catégorisez Vos URL
C'est le mouvement qui transforme un scan brut en un outil de diagnostic. Avant d'analyser quoi que ce soit, la première étape consiste à regrouper vos URL selon un modèle technique : pages produits, pages catégories, articles de blog, pages d'entreprise, etc. Sans cette découpe, vous travaillez à l'aveugle.
Pourquoi est-ce Obligatoire ?
Prenons un exemple concret. Votre scan montre qu'il y a 30 % de H1 en double sur l'ensemble du site. Ce chiffre est inquiétant. Cependant, dans son état actuel, il ne dit rien sur la cause du problème.
Maintenant, segmentez ces données par catégorie. Vous découvrirez que le doublon est largement concentré sur les pages produits. L'hypothèse se clarifie : la variante (couleur, taille) produit le même H1 car la variante n'est pas mentionnée dans le titre. La suggestion est également claire : en modifiant la règle de création du H1 produit pour ajouter la nature de la variante (par exemple, la couleur du produit).
Dans le modèle article, le même symptôme peut avoir une cause complètement différente : un balisage incorrect du modèle, un H1 codé en dur, un champ éditorial mal configuré. La suggestion sera également différente.
Logique à Retenir : Prendre Conscience de l'Anomalie → Segmenter par Modèle → Observer les Exemples → Comprendre le Modèle → Formuler une Suggestion Ciblée.
Ce processus de catégorisation donne un sens à toutes les analyses qui suivent. Pensez-y comme à un filtre que vous appliquez à vos données, vous permettant de passer d'une observation générale à une compréhension fine.
1. Profondeur du Scan : Diagnostiquez Rapidement Votre Architecture
Parmi les données obtenues lors d'un scan, le niveau de profondeur des pages est probablement le plus significatif. Beaucoup de gens l'ignorent, se contentant de vérifier que les pages importantes ne sont "pas trop profondes". C'est passer à côté de l'essentiel.
De Quoi Parlons-Nous ?
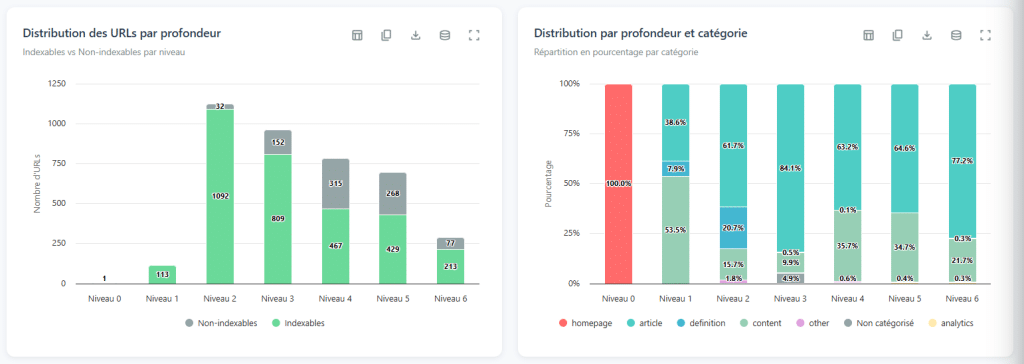
Le niveau de profondeur d'une page fait référence au nombre minimum de liens à suivre pour y accéder depuis la page d'accueil. C'est le chemin le plus court, pas n'importe quel chemin. Il est souvent simplifié en utilisant le terme "clic", mais ce qui est important, ce sont les liens. La page d'accueil est au niveau 0, les pages directement liées sont au niveau 1, et ainsi de suite.
Lecture de la Courbe de Profondeur
L'intérêt de cette analyse réside non pas dans les chiffres bruts, mais dans l'examen de la forme de la courbe de distribution. En l'observant, vous pouvez diagnostiquer de grands problèmes structurels.
Une courbe plate, lorsqu'elle s'étend sur des dizaines de niveaux (avec peu de pages à chaque couche) : cela indique presque certainement un paginage linéaire. Le site ne permet de passer que d'une page à l'autre ; page 1, page 2, page 3… Le navigateur doit passer par chaque étape pour atteindre le contenu à la fin de l'index. Résultat : les pages les plus profondes deviennent presque inaccessibles.
Une courbe à deux sommets (monte, descend, puis remonte) : c'est un signal presque orphelin. Le premier sommet représente le cœur d'un site bien connecté. Le deuxième sommet représente une série de pages liées à l'autre par seulement quelques liens en profondeur. Si vous coupez ces rares liens, cette partie du site devient complètement isolée. Résultat : très peu d'accessibilité, très peu d'autorité transmise.
Trop de profondeur, trop peu de pages (par exemple, cinq niveaux et seulement cinquante pages) : ici, il y a un problème d'efficacité dans les liens internes. Ces pages doivent être accessibles avec beaucoup moins de clics.
Oubliez la règle des "3 clics"
La célèbre règle "tout doit être accessible en 3 clics" est une légende tenace. Imaginez l'appliquer à Amazon ou à tout autre site à grande échelle : c'est tout simplement impossible. Au lieu de s'en tenir à un certain nombre, il est plus utile de penser en ratios.
Pour évaluer si votre profondeur est cohérente, prenez une base théorique simple. Supposons que la page d'accueil (niveau 0) découvre environ 100 pages. Ensuite, pensez que chaque nouvelle page découvre en moyenne 10 pages supplémentaires. Résultat : environ 100 pages au niveau 1, 1 000 pages au niveau 2, 10 000 pages au niveau 3.
Votre objectif n'est pas de correspondre exactement à ce modèle, mais de comparer votre profondeur réelle avec cette base théorique. Si votre site a 500 pages et que vous avez déjà 5 niveaux de profondeur, vous devez examiner les liens, car vous ne pouvez théoriquement couvrir ces pages qu'avec seulement 2 niveaux de profondeur.
2. Contenu similaire : le plagiat invisible
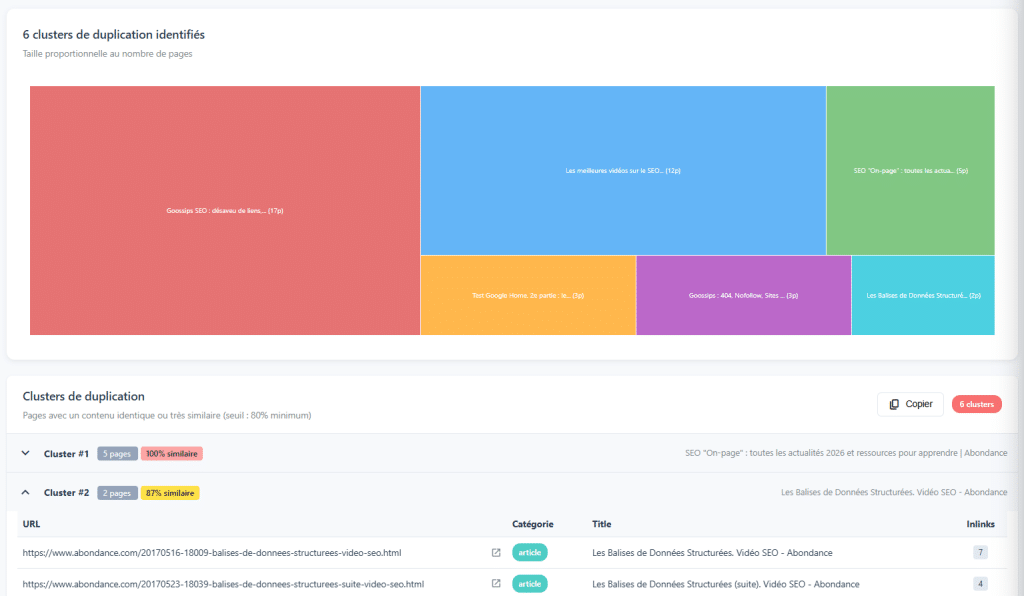
En matière de plagiat de contenu, tout le monde connaît le DUST (URL dupliquée, même texte) : deux URL différentes présentant exactement le même contenu. Il est facile de le détecter et généralement simple à corriger. Cependant, il existe une forme de plagiat plus insidieuse : le contenu similaire.
Pages trop similaires
Le contenu similaire fait référence à des pages dont le contenu n'est pas exactement le même mais très semblable. Quelques mots changés, un paragraphe ajouté ou supprimé, une légère reformulation… mais fondamentalement un contenu similaire. Les algorithmes de détection (comme le Simhash utilisé par de nombreux navigateurs) identifient ces similarités en comparant les empreintes de contenu.
Ces pages posent un véritable problème. Elles répartissent l'autorité entre plusieurs URL, au lieu de la concentrer en un seul endroit. Elles s'épuisent mutuellement dans leur positionnement. Et elles envoient un signal de contenu de faible valeur à Google. Dans certains cas, la bonne décision est de combiner ces contenus en une seule page plus riche et plus pertinente.
Attention aux faux positifs
C'est un point d'attention important : toute similarité de contenu n'est pas nécessairement un problème.
Si vous gérez un site dans plusieurs langues et que vous avez des versions en en-GB et en en-US, il est tout à fait normal que ces pages soient presque identiques. Elles s'adressent à des marchés différents. La même logique s'applique aux pages géographiquement localisées : "plombier à Paris" et "plombier à Lyon" partagent souvent le même modèle avec de petites variations, et c'est intentionnel. Le contenu similaire est un signal à examiner, ce n'est pas un jugement automatique. L'analyse manuelle en arrière-plan détermine s'il s'agit d'un véritable problème ou d'un faux positif lié au contexte du site.
3. Structure Hn : Vos H2, H3, H4 sont-ils vraiment organisés ?
Lors de l'audit du balisage d'un site, le réflexe est de vérifier le H1 : est-il présent ? Est-il unique ? Est-il pertinent ? C'est bien. Cependant, la structure des titres d'une page ne se limite pas au H1. C'est toute la hiérarchie qui organise le contenu et aide les moteurs à comprendre le contenu (du H1 au H6).
Problèmes invisibles
Analyser la structure Hn à l'échelle d'un scan permet de détecter des anomalies systémiques qui ne se révèlent pas simplement en vérifiant le H1.
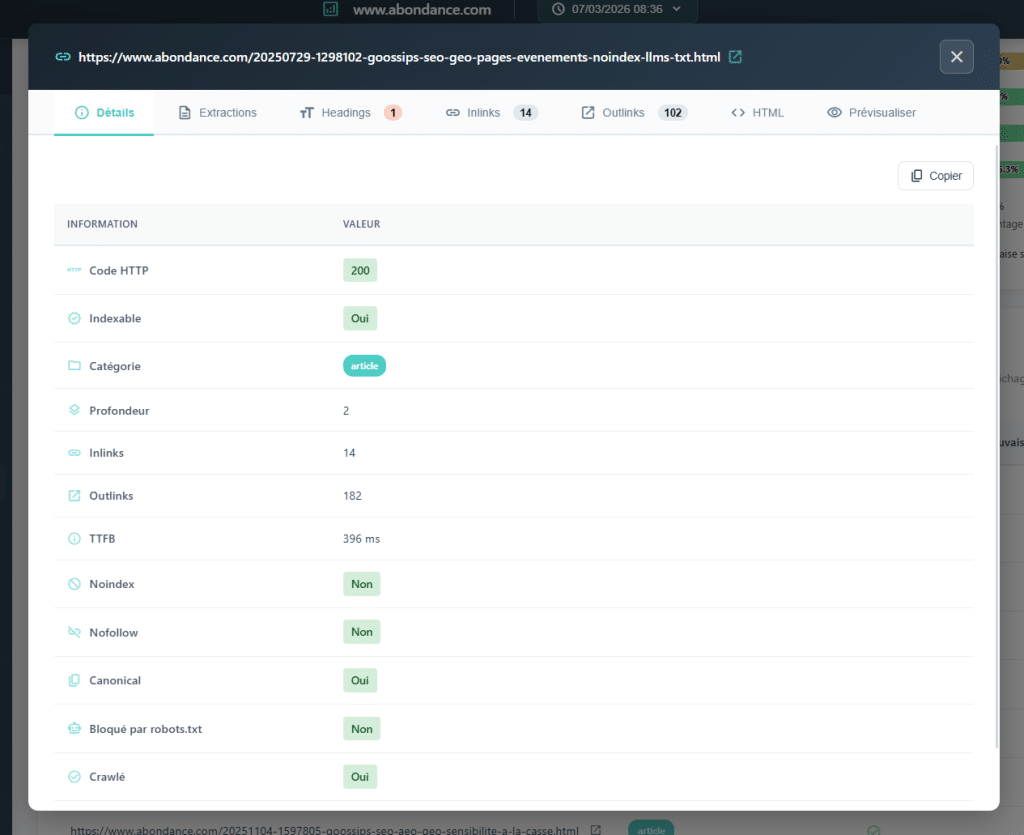
Sauter des niveaux : passer directement d'un H1 à un H3, sans H2 intermédiaire. Cela constitue une rupture dans la logique hiérarchique du document. Absence de H1, présence de H2, incohérences structurelles courantes. Structures complètement désordonnées, signe d'un contenu marqué sans un modèle ou une méthode bien conçue.
De plus, la duplication massive de H2 est un symptôme qui est souvent invisible lorsque vous ne regardez que les H1. Cela peut soulever un problème de modèle : des blocs réutilisés d'une page à l'autre (widgets, modules de barre latérale, pieds de page marqués comme H2…) polluent la structure de titre de chaque page.
Pourquoi est-ce important ?
Google utilise les balises Hn pour comprendre la structure thématique d'une page. Une hiérarchie cohérente aide les moteurs à identifier les sujets principaux et secondaires abordés. Au-delà du SEO, c'est également une question d'accessibilité : les lecteurs d'écran utilisent cette hiérarchie pour naviguer dans le contenu.
Le plus grand avantage de cette analyse est de signaler les erreurs de modèle. Un problème de structure Hn récurrent sur des centaines de pages est souvent un problème de modèle unique à corriger et a un impact considérable.
En résumé
Ces trois analyses ne remplacent pas les contrôles classiques d'un audit technique. Elles les complètent. Une fois maîtrisées, elles offrent une série de perspectives qui élargissent vos angles d'observation.
Le point le plus important à retenir est une réalité qui dépasse ces trois exemples : un crawl n'est pas un but, mais un outil de diagnostic. Les données brutes n'ont aucun sens sans interprétation. La véritable valeur d'un audit technique réside dans la capacité à lire les motifs, à comprendre les causes et à formuler des recommandations applicables. Et tout commence par l'habitude de catégoriser avant l'analyse.
Les visuels de cet article ont été créés avec Scouter, un crawler SEO open source et auto-hébergé. Il est disponible sur lokoe.fr/crawler-seo-scouter.





































Commentaires
(8 Commentaires)