
When you scan a website, the first reflex is usually the same: diving into the list of HTTP codes, filtering out 404 errors, tracking duplicate titles, and checking whether each page has an H1. These analyses are essential. They form the basis of a serious technical audit, and no one should skip them.
However, the richness of a scan is not limited to this. Behind the classic indicators, there are less common analyses that shed valuable light on the true health of the site. This article presents three of them. Not to replace the usual checks, but perhaps to add analytical angles that you haven't used yet.
The visual examples in this article are taken from Scouter, an open-source and self-hosted SEO crawler. However, the principles described here are valid regardless of the tool you use.
Before getting to the essence of the topic, there is a prerequisite.
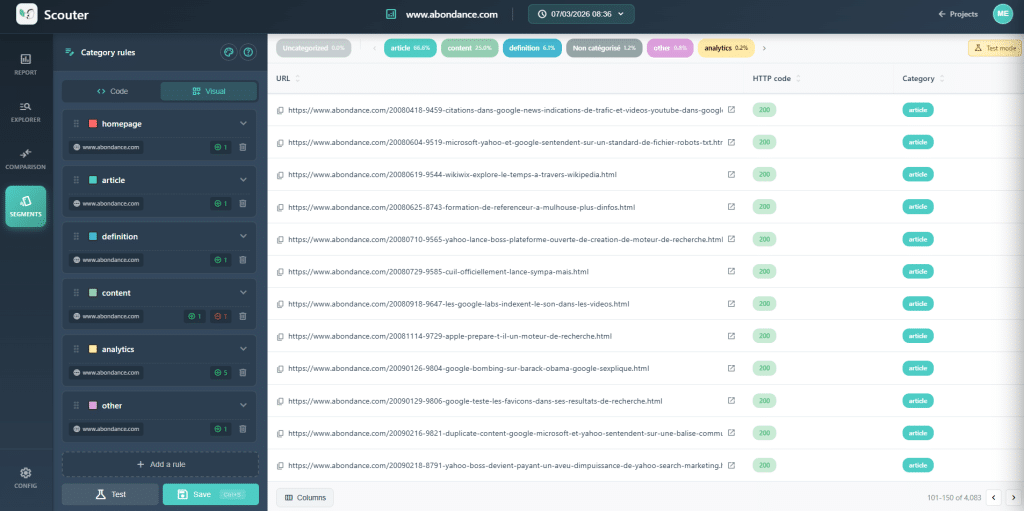
Before Any Analysis: Categorize Your URLs
This is the action that transforms a raw scan into a diagnostic tool. Before analyzing anything, the first step is to group your URLs according to a technical template: product pages, category pages, blog posts, corporate pages, etc. Without this categorization, you are working blindly.
Why Is This Mandatory?
Let's take a concrete example. Your scan shows that there is a 30% rate of duplicate H1 across the site. This figure is alarming. However, in its current state, it says nothing about the cause of the problem.
Now, separate this data by category. You will discover that the duplication largely focuses on product pages. The hypothesis becomes clear: the variant (color, size) produces the same H1 because the variant is not included in the title. The suggestion is also clear: by changing the rule for creating the product H1, add the nature of the variant (for example, the color of the product).
In the article template, the same symptom may have a completely different cause: poor markup of the template, a hardcoded H1, a misconfigured editorial field. The suggestion will also differ.
The Logic to Keep in Mind: Recognize the Anomaly → Separate by Template → Observe Examples → Understand the Pattern → Create a Targeted Suggestion.
This categorization process adds meaning to all subsequent analyses. Think of it as a filter applied to your data, allowing you to transition from a general observation to a nuanced understanding.
1. Scan Depth: Quickly Diagnose Your Architecture
Among the data obtained during a scan, the depth level of pages is probably the most meaningful. Many people overlook this and are content to check that important pages are "not too deep." This is missing the essence.
What Are We Talking About?
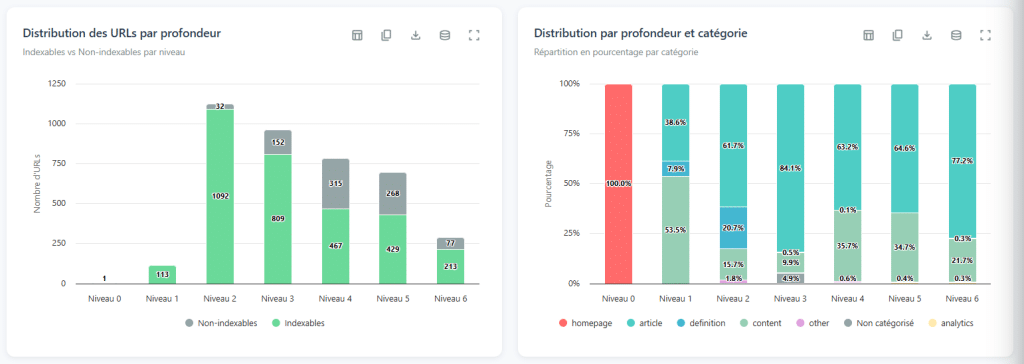
The depth level of a page refers to the minimum number of links that must be followed to access it from the homepage. This is the shortest route, not just any path. It is often simplified using the term "clicks," but what matters are the links. The homepage is at level 0, the pages it directly links to are at level 1, and it continues like this.
Reading the Depth Curve
The interest in this analysis lies not in the raw numbers, but in examining the shape of the distribution curve. Just by looking at it, you can diagnose significant structural issues.
A flat curve, when spread over dozens of levels (with a small number of pages at each layer): this is almost certainly a sign of linear pagination. The site only allows moving from one page to another; page 1, page 2, page 3… The browser must pass through every stage to reach the content at the end of the index. The result: the deepest pages become nearly inaccessible.
A two-peaked curve (rises, falls, then rises again): this is a signal of almost orphaned content. The first peak represents the heart of a well-connected site. The second peak represents a series of pages connected to the first by only a few links in depth. If you cut these rare connections, this part of the site becomes completely isolated. The result: very little accessibility, very little authority transferred.
Too much depth, too few pages (for example, five levels and only fifty pages): here, there is an efficiency issue in internal linking. These pages should be accessible with much fewer clicks to ensure they are reachable.
Forget the "3 Clicks" Rule
The famous rule that "everything should be accessible within 3 clicks" is a persistent myth. Imagine applying it to Amazon or any large-scale site: it is simply impossible. Instead of sticking to a specific number, it is more beneficial to think in ratios.
To evaluate whether your depth is consistent, take a simple theoretical basis. Assume the homepage (level 0) discovers about 100 pages. Then, think that each new page discovers an average of 10 more pages. The result: about 100 pages at level 1, 1,000 pages at level 2, and 10,000 pages at level 3.
Your goal is not to conform exactly to this model, but to compare your actual depth with this theoretical basis. If your site has 500 pages and you already have 5 depth levels, you should investigate the linking because theoretically, you can cover these pages with only 2 depth levels.
2. Close Copy: Invisible Copying
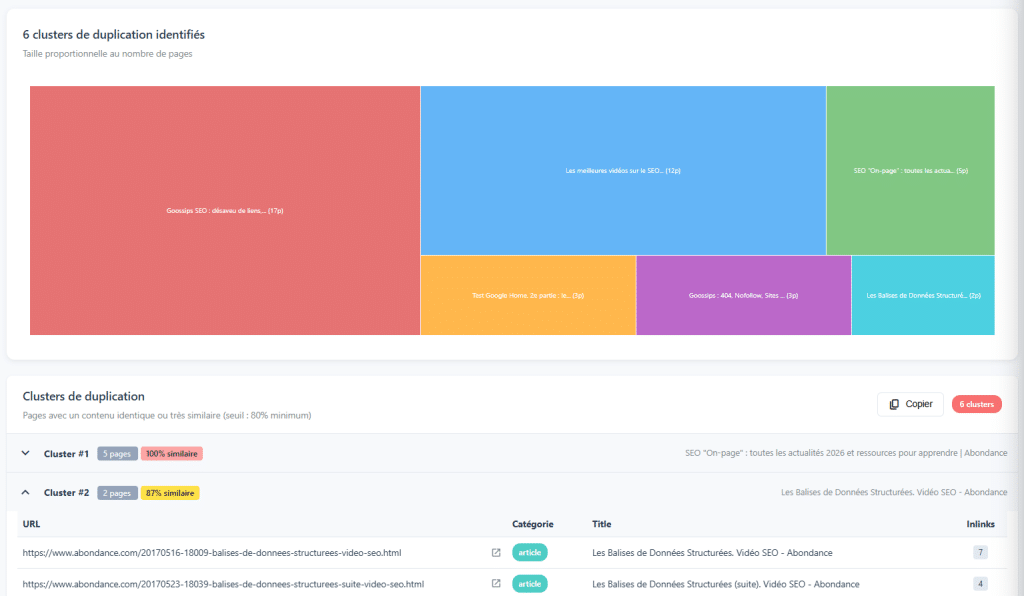
When it comes to content duplication, everyone knows DUST (Duplicate URL, Same Text): two different URLs presenting exactly the same content. This is easy to detect and usually simple to fix. However, there is a more insidious form of copying: close copy.
Pages That Are Extremely Similar to Each Other
Close copy refers to pages that are very similar, even if the content is not exactly the same. Some words changing, adding or removing a paragraph, slight rephrasing… but fundamentally similar content. Detection algorithms (like Simhash, used by many crawlers) identify these similarities by comparing content traces.
These pages pose a real problem. They distribute authority across multiple URLs instead of concentrating it in one place. They consume each other in positioning. And they send a low-value content signal to Google. In some cases, the right decision is to combine this content into a richer and more relevant single page.
Beware of False Positives
This is an important point of caution: any content similarity is not necessarily a problem.
If you manage a site in multiple languages and have en-GB and en-US versions, it is completely normal for these pages to be almost identical. They target different markets. The same logic applies to geographically localized pages: "plumber in Paris" and "plumber in Lyon" often share the same template with slight variations, and this is intentional. Close copy is a signal to be investigated, not an automatic judgment. It is the manual analysis in the background that determines whether it is a real problem or a false positive dependent on the context of the site.
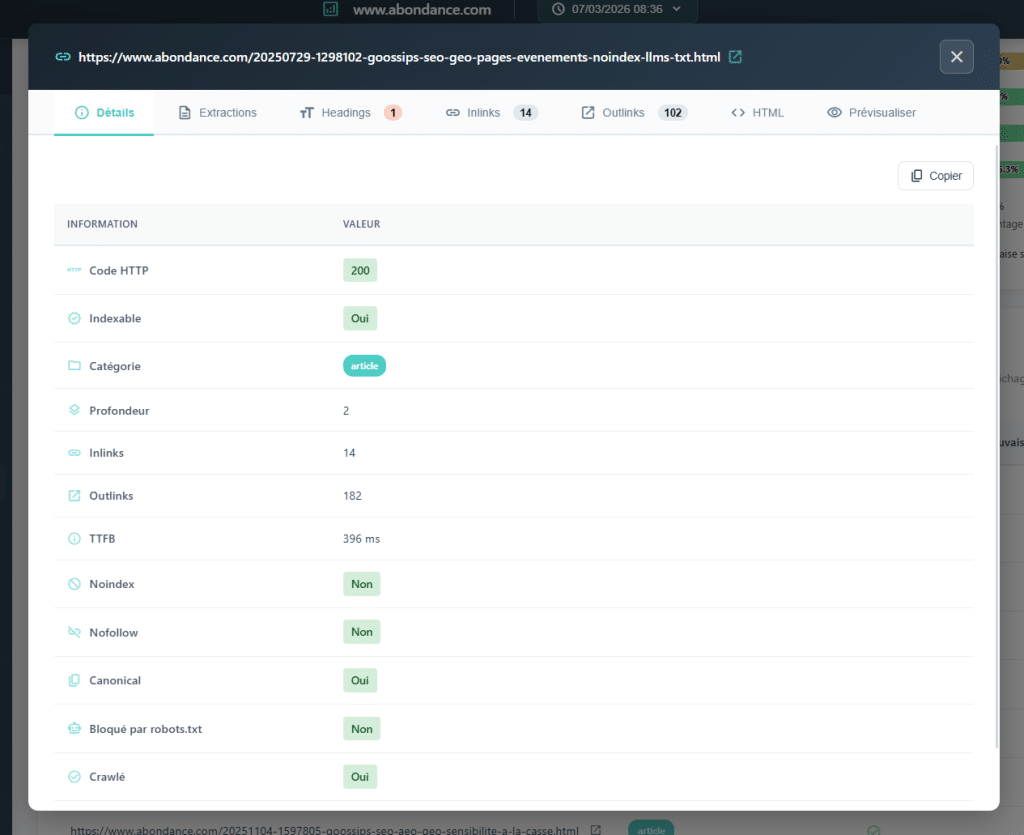
3. Hn Structure: Are Your H2s, H3s, H4s Really Organized?
When auditing a site's markup, the reflex is to check H1: is it present? Is it unique? Is it relevant? That's good. However, a page's heading structure is not limited to H1. It is the entire hierarchy that organizes the content and helps engines understand the content (from H1 to H6).
Visible Issues
Analyzing Hn structure on a crawl scale allows you to detect systemic abnormalities that do not arise from merely checking H1.
Jumping between levels: directly transitioning from H1 to H3 on a page, without the H2 intermediary layer. This represents a break in the hierarchical logic of the document. Missing H1s with existing H2s are common structural inconsistencies. Completely irregular structures indicate poorly designed templates or content marked without a method.
Additionally, the extensive duplication of H2s is often an unseen symptom when only looking at H1s. This may reveal a template issue: reused blocks (widgets, sidebar modules, footers marked as H2…) pollute the heading structure of each page.
Why is it Important?
Google uses Hn tags to understand the thematic structure of a page. A consistent hierarchy helps engines identify the main and subtopics being addressed. Beyond SEO, this is also an accessibility issue: screen readers use this hierarchy to navigate the content.
The greatest benefit of this analysis is its ability to highlight template errors. A recurring Hn structure issue across hundreds of pages is often just a single template problem that needs fixing and can create a significant impact.
In Summary
These three analyses do not replace the classic checks of a technical audit. They complement them. Once mastered, they offer a range of perspectives that broaden your observation angles.
The most important point to remember is a truth that goes beyond these three examples: a crawl is not a goal, but a diagnostic tool. Raw data means nothing without interpretation. The real value of a technical audit lies in the ability to read patterns, understand causes, and provide actionable recommendations. And it all starts with the habit of categorizing before analysis.
The visuals in this article were created using Scouter, an open-source and self-hosted SEO crawler. It is available at lokoe.fr/crawler-seo-scouter.






































Comments
(8 Comments)