
Wenn Sie eine Website durchsuchen, ist der erste Reflex normalerweise derselbe: in die Liste der HTTP-Codes eintauchen, 404-Fehler filtern, doppelte Überschriften verfolgen und überprüfen, ob jede Seite eine H1 hat. Diese Analysen sind unerlässlich. Sie bilden die Grundlage einer ernsthaften technischen Prüfung, und niemand sollte darauf verzichten.
Doch der Reichtum einer Analyse beschränkt sich nicht darauf. Hinter den klassischen Indikatoren verbergen sich weniger verbreitete Analysen, die wertvolle Einblicke in die tatsächliche Gesundheit der Website bieten. In diesem Artikel werden drei davon vorgestellt. Nicht um die gewohnten Kontrollen zu ersetzen, sondern vielleicht um Analyseansätze hinzuzufügen, die Sie noch nicht genutzt haben.
Die visuellen Beispiele in diesem Artikel stammen von Scouter, einem Open-Source-SEO-Crawler, der selbst gehostet werden kann. Die hier beschriebenen Prinzipien gelten jedoch unabhängig von dem Tool, das Sie verwenden.
Bevor wir in die Materie eintauchen, gibt es eine Voraussetzung.
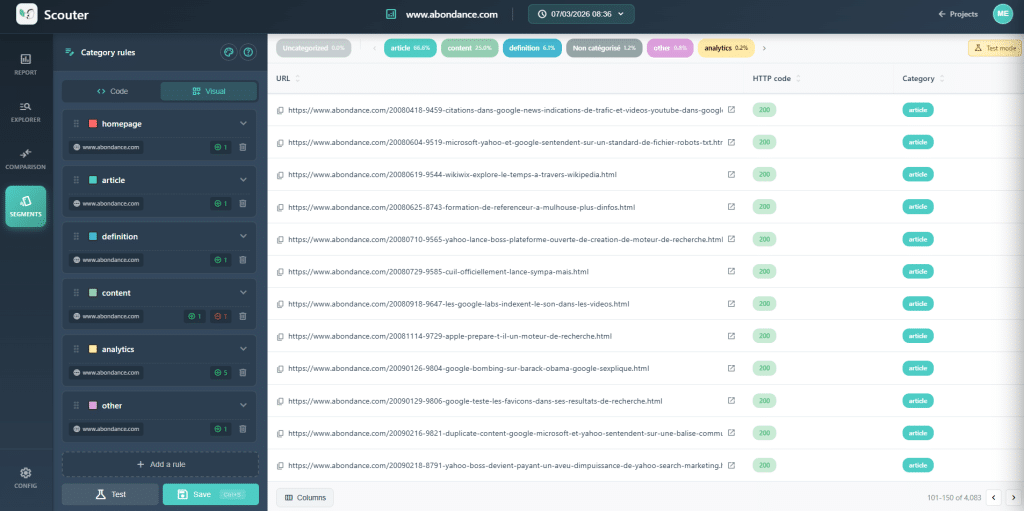
Vor jeder Analyse: Kategorisieren Sie Ihre URLs
Dies ist der Schritt, der einen rohen Crawl in ein Diagnosewerkzeug verwandelt. Bevor Sie irgendetwas analysieren, besteht der erste Schritt darin, Ihre URLs nach technischem Schema zu gruppieren: Produktseiten, Kategorieseiten, Blogbeiträge, Unternehmensseiten usw. Ohne diese Einteilung arbeiten Sie blind.
Warum ist das notwendig?
Nehmen wir ein konkretes Beispiel. Ihr Crawl zeigt, dass es auf der gesamten Website einen Anteil von 30 % doppelten H1 gibt. Diese Zahl ist beunruhigend. Aber in ihrem aktuellen Zustand sagt sie nichts über die Ursache des Problems aus.
Jetzt teilen Sie diese Daten nach Kategorie auf. Sie werden feststellen, dass sich die Duplikate stark auf Produktseiten konzentrieren. Die Hypothese wird klar: Varianten (Farbe, Größe) produzieren dieselbe H1, weil die Varianten nicht im Titel enthalten sind. Der Vorschlag ist ebenfalls klar: Ändern Sie die Regel zur Erstellung der Produkt-H1, um die Eigenschaften der Variante (z. B. die Farbe des Produkts) hinzuzufügen.
Im Artikel-Template kann dasselbe Symptom jedoch eine ganz andere Ursache haben: schlechte Markierung des Templates, fest kodierte H1, falsch konfiguriertes redaktionelles Feld. Der Vorschlag wird ebenfalls anders sein.
Logik, die man sich merken sollte: Anomalie erkennen → Nach Template kategorisieren → Beispiele beobachten → Muster verstehen → Zielgerichteten Vorschlag erstellen.
Dieser Kategorisierungsprozess verleiht allen nachfolgenden Analysen Bedeutung. Denken Sie daran, es als einen Filter zu betrachten, den Sie auf Ihre Daten anwenden, der Ihnen hilft, von einer allgemeinen Beobachtung zu einem feinen Verständnis überzugehen.
1. Crawltiefe: Diagnostizieren Sie Ihre Architektur schnell
Unter den Daten, die während eines Crawls erfasst werden, ist das Tiefenniveau der Seiten wahrscheinlich das bedeutendste. Viele ignorieren dies und begnügen sich damit, zu überprüfen, ob wichtige Seiten "nicht zu tief" sind. Das ist es, was man verpasst.
Worüber sprechen wir?
Das Tiefenniveau einer Seite bezieht sich auf die minimale Anzahl von Links, die erforderlich sind, um von der Startseite darauf zuzugreifen. Dies ist der kürzeste Weg, nicht irgendein Weg. Es wird oft vereinfacht mit dem Begriff "Klick", aber entscheidend sind die Links. Die Startseite ist auf Stufe 0, die Seiten, auf die sie direkt verlinkt, sind auf Stufe 1, und so geht es weiter.
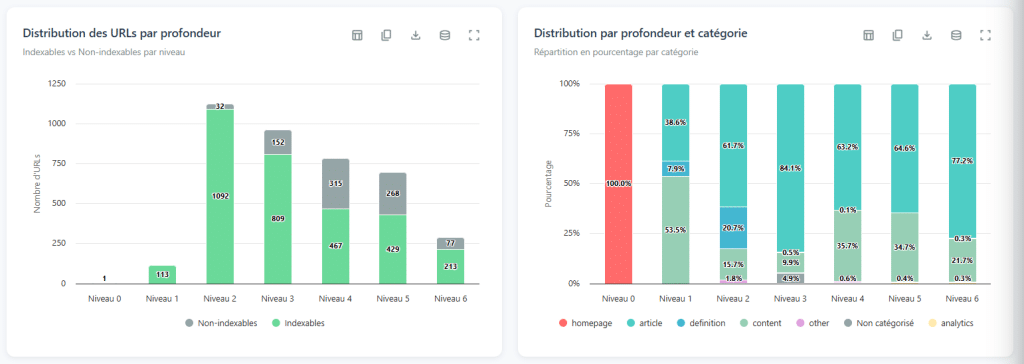
Lesen der Tiefenkurve
Das Interesse an dieser Analyse liegt nicht in den Rohzahlen, sondern in der Untersuchung der Form der Verteilungskurve. Allein durch einen Blick darauf können Sie große strukturelle Probleme diagnostizieren.
Eine gerade Kurve, die sich über Dutzende von Ebenen erstreckt (mit wenigen Seiten in jeder Schicht): Das ist fast ein sicheres Zeichen für lineares Paging. Die Website erlaubt nur den Übergang von einer Seite zur anderen; Seite 1, Seite 2, Seite 3… Der Browser muss jede Stufe durchlaufen, um auf die Inhalte am Ende des Index zuzugreifen. Das Ergebnis: Die tiefsten Seiten werden fast unerreichbar.
Zwei Gipfel einer Kurve (steigt, fällt, steigt dann wieder): das ist ein fast verwaister Abschnitt des Signals. Der erste Gipfel repräsentiert das Herz einer gut verlinkten Seite. Der zweite Gipfel steht für eine Reihe von Seiten, die nur durch einige wenige Links in der Tiefe mit der anderen verbunden sind. Wenn Sie diese seltenen Links trennen, wird dieser Teil der Seite vollständig isoliert. Ergebnis: sehr geringe Zugänglichkeit, sehr geringe übertragene Autorität.
Zu viel Tiefe, zu wenige Seiten (zum Beispiel fünf Ebenen und nur fünfzig Seiten): hier gibt es ein Effizienzproblem bei den internen Links. Diese Seiten sollten mit viel weniger Klicks zugänglich sein, um sicherzustellen, dass sie erreichbar sind.
Vergessen Sie die "3-Klick"-Regel
Die berühmte Regel "alles sollte in 3 Klicks erreichbar sein" ist eine hartnäckige Legende. Stellen Sie sich vor, Sie wenden dies auf Amazon oder eine andere groß angelegte Seite an: das ist einfach unmöglich. Statt sich an eine bestimmte Zahl zu halten, ist es hilfreicher, über Verhältnisse nachzudenken.
Um zu bewerten, ob Ihre Tiefe konsistent ist, nehmen Sie eine einfache theoretische Grundlage. Angenommen, die Startseite (Ebene 0) entdeckt etwa 100 Seiten. Dann denken Sie, dass jede neue Seite im Durchschnitt 10 weitere Seiten entdeckt. Ergebnis: etwa 100 Seiten auf Ebene 1, 1.000 Seiten auf Ebene 2, 10.000 Seiten auf Ebene 3.
Ihr Ziel ist es nicht, diesem Modell genau zu entsprechen, sondern Ihre tatsächliche Tiefe mit dieser theoretischen Grundlage zu vergleichen. Wenn Ihre Seite 500 Seiten hat und Sie bereits 5 Tiefenebenen haben, sollten Sie die Verlinkung überprüfen, da Sie diese Seiten theoretisch nur mit 2 Tiefenebenen abdecken können.
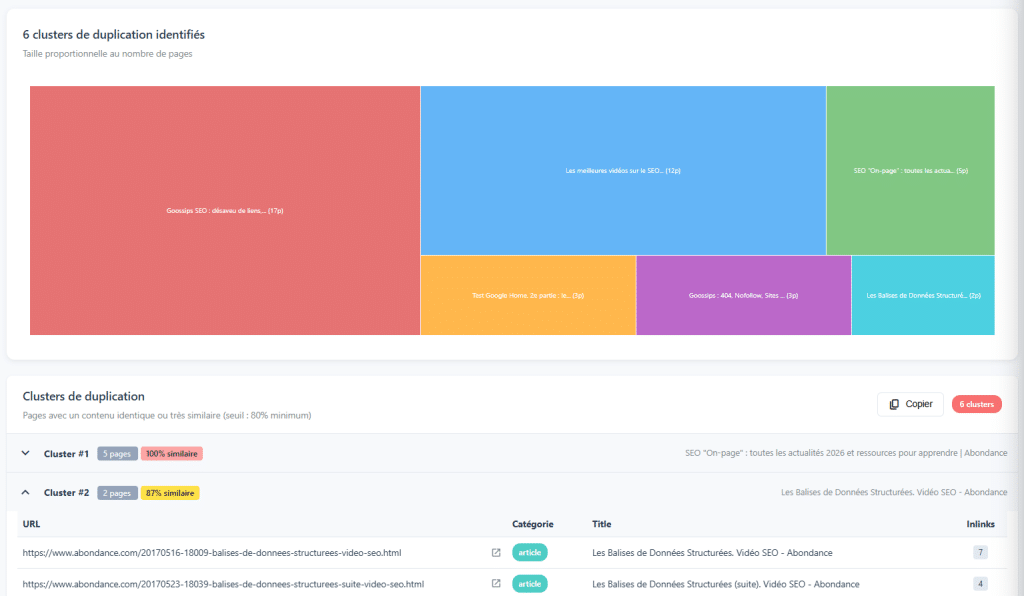
2. Nahkopie: Unsichtbares Kopieren
Wenn es um Inhaltskopien geht, kennt jeder DUST (Duplicate URL, Same Text): zwei verschiedene URLs, die genau denselben Inhalt anbieten. Dies zu erkennen ist einfach und oft leicht zu beheben. Es gibt jedoch eine heimtückischere Form des Kopierens: Nahkopie.
Seiten, die sich zu ähnlich sind
Eine Nahkopie bezieht sich auf Seiten, deren Inhalte zwar nicht identisch, aber sehr ähnlich sind. Einige Wörter ändern sich, ein Absatz wird hinzugefügt oder entfernt, eine leichte Umformulierung… aber im Grunde ähnlicher Inhalt. Erkennungsalgorithmen (wie Simhash, der von vielen Browsern verwendet wird) definieren diese Ähnlichkeiten durch den Vergleich von Inhaltsmustern.
Diese Seiten stellen ein echtes Problem dar. Sie verteilen die Autorität über mehrere URLs, anstatt sie an einem Ort zu konzentrieren. Sie verbrauchen sich gegenseitig bei der Positionierung. Und sie senden Google ein Signal für minderwertigen Inhalt. In einigen Fällen besteht die richtige Entscheidung darin, diese Inhalte in einer reichhaltigeren und relevanteren einzelnen Seite zu kombinieren.
Achten Sie auf falsche Positiva
Dies ist ein wichtiger Punkt: Jede Ähnlichkeit im Inhalt ist nicht zwangsläufig ein Problem.
Wenn Sie eine Website in vielen Sprachen verwalten und über en-GB und en-US-Versionen verfügen, ist es völlig normal, dass diese Seiten nahezu identisch sind. Sie richten sich an unterschiedliche Märkte. Dasselbe gilt für geografisch lokalisierten Seiten: "Installateur in Paris" und "Installateur in Lyon" teilen oft dasselbe Template mit kleinen Variationen, und das ist beabsichtigt. Nahkopie ist ein Signal, das untersucht werden sollte, kein automatisches Urteil. Die manuelle Analyse im Hintergrund entscheidet, ob es sich um ein echtes Problem oder um ein falsches Positiv im Kontext der Seite handelt.
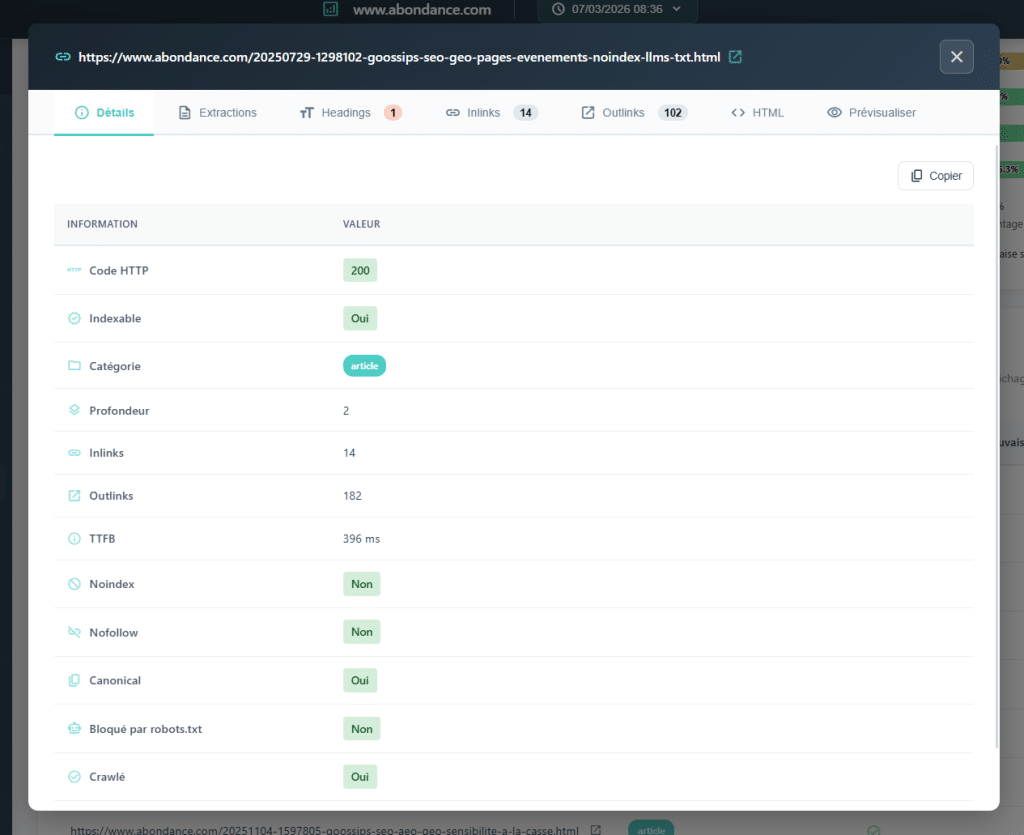
3. Hn-Struktur: Sind Ihre H2, H3, H4 wirklich ordentlich?
Wenn Sie die Markup einer Seite überprüfen, ist der Reflex, H1 zu überprüfen: Ist sie vorhanden? Ist sie einzigartig? Ist sie relevant? Das ist gut. Aber die Überschriftenstruktur einer Seite beschränkt sich nicht nur auf H1. Es ist die gesamte Hierarchie, die den Inhalt organisiert und den Maschinen hilft, den Inhalt zu verstehen (von H1 bis H6).
Unsichtbare Probleme
Die Analyse der Hn-Struktur auf einer Scan-Ebene ermöglicht es, systematische Anomalien zu erkennen, die nicht durch die bloße Überprüfung von H1 sichtbar werden.
Sprünge in den Ebenen: ein direktes Springen von H1 zu H3 auf einer Seite, ohne die H2-Zwischenschicht. Dies ist ein Bruch in der hierarchischen Logik des Dokuments. Fehlende H1s und vorhandene H2s sind häufige strukturelle Inkonsistenzen. Völlig unregelmäßige Strukturen sind ein Zeichen für einen schlecht gestalteten Template oder für Inhalte, die ohne Methode markiert wurden.
Außerdem ist die weitgehende Kopie von H2 ein Symptom, das oft nicht sichtbar ist, wenn man nur auf H1 schaut. Dies kann ein Problem mit dem Template aufwerfen: wiederverwendete Blöcke (Widgets, Sidebar-Module, als H2 markierte Fußzeilen…) verschmutzen die Kopfstruktur jeder Seite.
Warum ist das wichtig?
Google verwendet Hn-Tags, um die thematische Struktur einer Seite zu verstehen. Eine konsistente Hierarchie hilft den Maschinen, die Haupt- und Nebenthemen zu identifizieren. Über SEO hinaus ist dies auch eine Frage der Zugänglichkeit: Screenreader nutzen diese Hierarchie, um sich im Inhalt zurechtzufinden.
Der größte Vorteil dieser Analyse besteht darin, Template-Fehler zu kennzeichnen. Ein Hn-Strukturproblem, das sich auf Hunderten von Seiten wiederholt, ist oft ein einziges Template-Problem, das behoben werden kann und große Auswirkungen hat.
Zusammenfassend
Diese drei Analysen ersetzen nicht die klassischen Kontrollen eines technischen Audits. Sie ergänzen sie. Sobald Sie darin geübt sind, bieten sie eine Reihe von Perspektiven, die Ihre Beobachtungswinkel erweitern.
Der wichtigste Punkt, der nicht vergessen werden sollte, ist eine Tatsache, die über diese drei Beispiele hinausgeht: ein Crawl ist kein Ziel, sondern ein Diagnosewerkzeug. Rohdaten bedeuten ohne Interpretation nichts. Der wahre Wert eines technischen Audits liegt in der Fähigkeit, Muster zu lesen, Ursachen zu verstehen und umsetzbare Empfehlungen abzugeben. Und alles beginnt mit der Gewohnheit, vor der Analyse zu kategorisieren.
Die Grafiken in diesem Artikel wurden mit Scouter, einem Open-Source- und selbstgehosteten SEO-Crawler, erstellt. Sie sind unter lokoe.fr/crawler-seo-scouter verfügbar.






































Kommentare
(8 Kommentare)