
Cuando realizas un escaneo en un sitio web, el primer reflejo suele ser el mismo: sumergirse en la lista de códigos HTTP, filtrar errores 404, rastrear encabezados duplicados y verificar si cada página tiene un H1. Estos análisis son obligatorios. Constituyen la base de una auditoría técnica seria y nadie debería prescindir de ellos.
Sin embargo, la riqueza de un escaneo no se limita a esto. Detrás de los indicadores clásicos, hay análisis menos comunes que arrojan una valiosa luz sobre la verdadera salud del sitio. En este artículo se presentan tres de ellos. No para reemplazar los controles habituales, sino quizás para añadir ángulos de análisis que aún no has utilizado.
Los ejemplos visuales en este artículo provienen de Scouter, un rastreador SEO de código abierto y autoalojado. Sin embargo, los principios aquí descritos son válidos independientemente de la herramienta que utilices.
Antes de entrar en el meollo del asunto, hay un requisito previo.
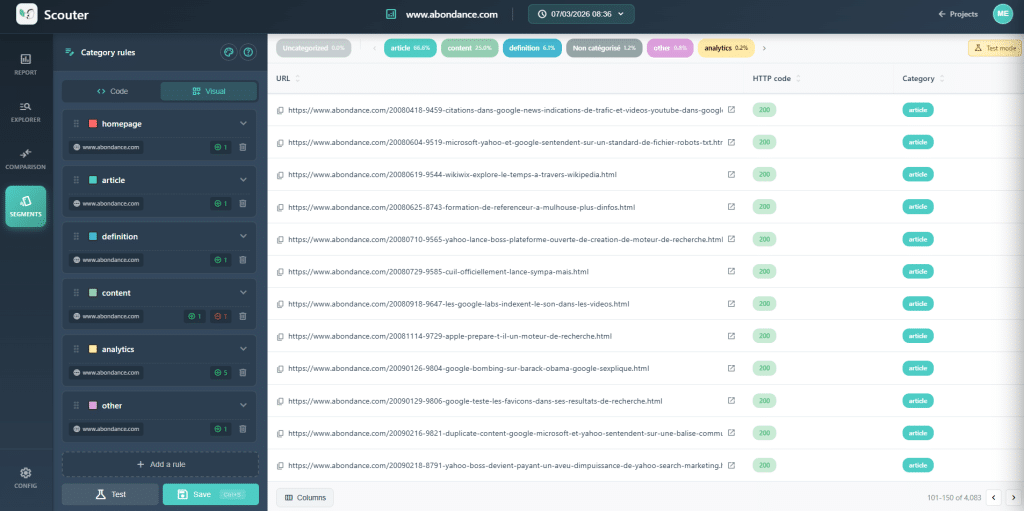
Antes de Cualquier Análisis: Categoriza tus URLs
Este es el movimiento que transforma un escaneo bruto en una herramienta de diagnóstico. Antes de analizar cualquier cosa, el primer paso es agrupar tus URLs según una plantilla técnica: páginas de productos, páginas de categorías, entradas de blog, páginas corporativas, etc. Sin este corte, estás trabajando a ciegas.
¿Por Qué Es Esto Obligatorio?
Tomemos un ejemplo concreto. Tu escaneo muestra que hay un 30% de H1 duplicados en todo el sitio. Esta cifra es alarmante. Sin embargo, tal como está, no dice nada sobre la causa del problema.
Ahora, separa estos datos por categoría. Descubrirás que la duplicación se centra en gran medida en las páginas de productos. La hipótesis se clarifica: la variante (color, tamaño) produce el mismo H1 porque la variante no está en el encabezado. La sugerencia es clara: cambiar la regla de creación del H1 del producto para incluir la naturaleza de la variante (por ejemplo, el color del producto).
En la plantilla de artículo, el mismo síntoma puede tener una causa completamente diferente: mala marcación de la plantilla, un H1 codificado de forma fija, un campo editorial mal configurado. La sugerencia también será diferente.
Lógica a Tener en Cuenta: Reconocer la Anomalía → Separar por Plantilla → Observar Ejemplos → Comprender el Patrón → Crear una Sugerencia Dirigida.
Este proceso de categorización da significado a todos los análisis que siguen. Piensa en ello como un filtro que aplicas a tus datos, permitiéndote pasar de una observación general a una comprensión más sutil.
1. Profundidad de Escaneo: Diagnostica Rápidamente tu Estructura
Entre los datos obtenidos durante un escaneo, el nivel de profundidad de las páginas es probablemente el más significativo. Muchas personas lo ignoran y se limitan a comprobar que las páginas importantes "no están demasiado profundas". Esto es perder de vista lo esencial.
¿De Qué Hablamos?
El nivel de profundidad de una página se refiere al número mínimo de enlaces que deben seguirse desde la página de inicio para acceder a ella. Este es el camino más corto, no cualquier camino. A menudo se simplifica utilizando el término "clic", pero lo importante son los enlaces. La página de inicio está en el nivel 0, las páginas a las que enlaza directamente están en el nivel 1, y así sucesivamente.
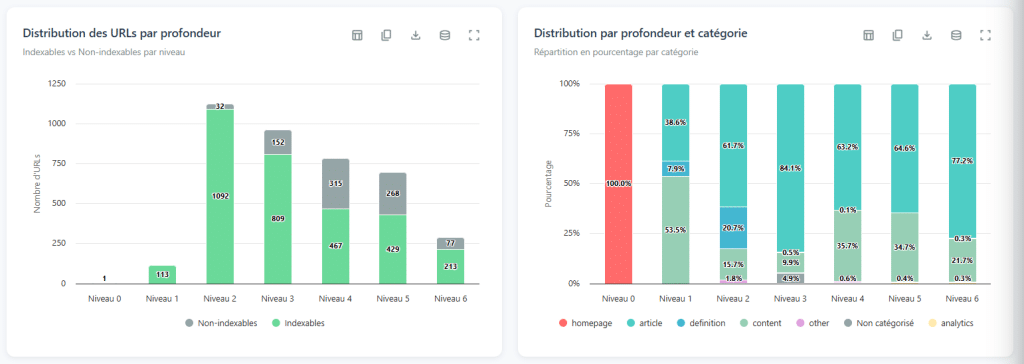
Lectura de la Curva de Profundidad
El interés en este análisis no radica en los números brutos, sino en el estudio de la forma de la curva de distribución. Solo con mirarla, puedes diagnosticar grandes problemas estructurales.
Una curva plana, cuando se extiende a través de decenas de niveles (con pocas páginas en cada capa): esto es casi un indicio seguro de paginación lineal. El sitio solo permite pasar de una página a otra; página 1, página 2, página 3… El navegador debe pasar por cada etapa para llegar al contenido al final del índice. Resultado: las páginas más profundas se vuelven casi inaccesibles.
Una curva de dos picos (sube, baja y luego vuelve a subir): esta es una señal de casi una sección huérfana. El primer pico representa el corazón de un sitio bien enlazado. El segundo pico representa una serie de páginas que están conectadas a la otra solo por unos pocos enlaces en profundidad. Si cortas estos enlaces raros, esta parte del sitio queda completamente aislada. Resultado: muy poca accesibilidad, muy poca autoridad transferida.
Demasiada profundidad, muy pocas páginas (por ejemplo, cinco niveles y solo cincuenta páginas): aquí hay un problema de eficiencia en los enlaces internos. Estas páginas deben ser accesibles con mucho menos clics para asegurar su accesibilidad.
Olvida la Regla de "3 Clics"
La famosa regla de "todo debe ser accesible en 3 clics" es una leyenda persistente. Imagina aplicarla a Amazon o a cualquier sitio de gran escala: simplemente es imposible. En lugar de apegarse a un número específico, es más útil pensar en proporciones.
Para evaluar si tu profundidad es consistente, toma una base teórica simple. Supón que la página de inicio (nivel 0) descubre aproximadamente 100 páginas. Luego, considera que cada nueva página descubre un promedio de 10 páginas más. Resultado: aproximadamente 100 páginas en el nivel 1, 1,000 páginas en el nivel 2, 10,000 páginas en el nivel 3.
No se trata de ajustarse exactamente a este modelo, sino de comparar tu profundidad real con esta base teórica. Si tu sitio tiene 500 páginas y ya tienes 5 niveles de profundidad, deberías investigar la vinculación porque teóricamente solo puedes cubrir estas páginas con 2 niveles de profundidad.
2. Copia Cercana: Copia Invisible
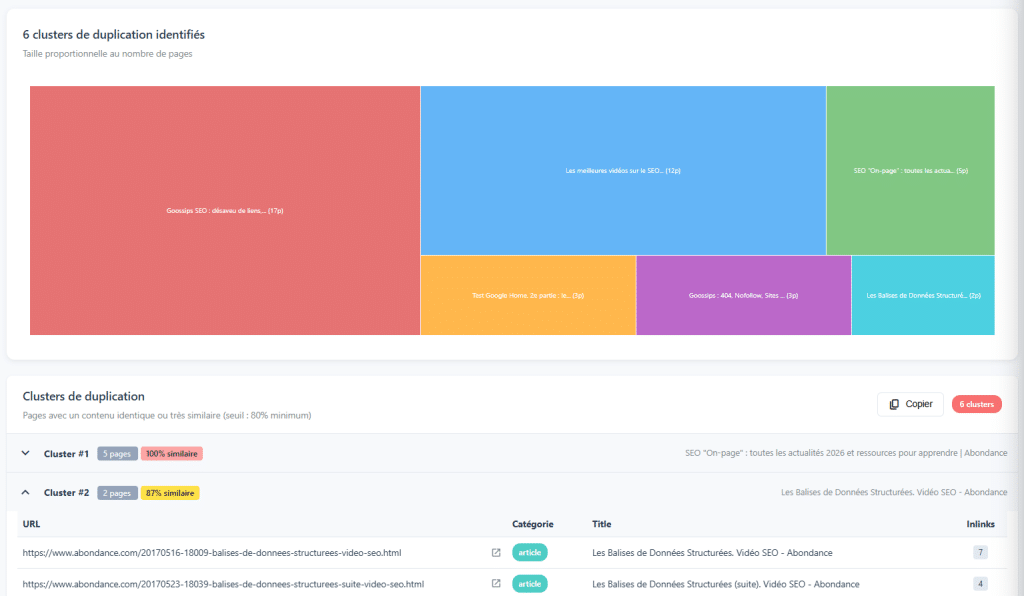
Cuando se trata de copia de contenido, todos conocen DUST (URL duplicada, mismo texto): dos URL diferentes que presentan exactamente el mismo contenido. Esto es fácil de detectar y generalmente es sencillo de corregir. Sin embargo, hay una forma de copia más insidiosa: copia cercana.
Páginas que se Parecen Demasiado Entre Sí
La copia cercana se refiere a páginas cuyo contenido, aunque no es exactamente el mismo, es muy similar. Algunos cambios de palabras, la adición o eliminación de un párrafo, una ligera reformulación... pero esencialmente contenido similar. Los algoritmos de detección (como Simhash, utilizado por muchos navegadores) definen estas similitudes comparando huellas de contenido.
Estas páginas representan un verdadero problema. Distribuyen la autoridad entre múltiples URL, en lugar de concentrarla en un solo lugar. Se consumen entre sí al posicionarse. Y envían una señal de contenido de bajo valor a Google. En algunos casos, la decisión correcta es combinar estos contenidos en una sola página más rica y relevante.
Cuidado con los Falsos Positivos
Este es un punto de atención importante: cualquier similitud de contenido no es necesariamente un problema.
Si gestionas un sitio en varios idiomas y tienes versiones en en-GB y en-US, es completamente normal que estas páginas sean casi idénticas. Están dirigidas a diferentes mercados. La misma lógica se aplica a las páginas geográficamente localizadas: "fontanero en París" y "fontanero en Lyon" suelen compartir el mismo esquema con pequeñas variaciones, y esto es intencional. La copia cercana es una señal que debe ser investigada, no un juicio automático. El análisis manual en el fondo es lo que determina si es un verdadero problema o un falso positivo dependiendo del contexto del sitio.
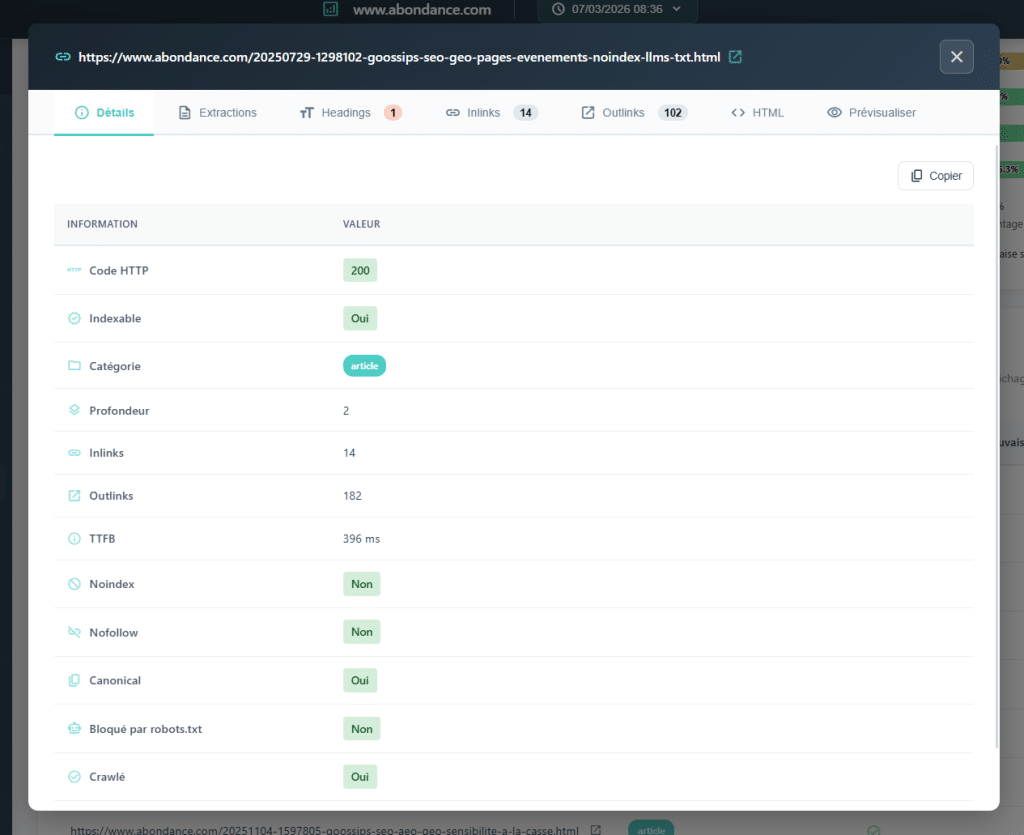
3. Estructura Hn: ¿Tus H2, H3, H4 están Realmente Organizados?
Al auditar la marcación de un sitio, el reflejo es comprobar el H1: ¿está presente? ¿Es único? ¿Es relevante? Eso está bien. Sin embargo, la estructura de encabezados de una página no se limita solo al H1. Es toda la jerarquía que organiza el contenido y ayuda a los motores a entender el contenido (desde H1 hasta H6).
Problemas Invisibles
Analizar la estructura Hn a escala de rastreo permite detectar anormalidades sistémicas que no se revelan al solo comprobar el H1.
Saltos en los niveles: pasar directamente de H1 a H3 en una página, sin la capa intermedia H2. Esto es una ruptura en la lógica jerárquica del documento. Faltas de H1, con H2 presentes, inconsistencias estructurales comunes. Estructuras completamente desordenadas, un signo de un contenido marcado sin un diseño o método bien pensado.
Además, la duplicación masiva de H2 es un síntoma que a menudo no se ve cuando solo se observan los H1. Esto puede plantear un problema de plantilla: bloques reutilizados de una página a otra (widgets, módulos de barra lateral, pies de página marcados como H2…) ensucian la estructura de encabezados de cada página.
¿Por qué es importante?
Google utiliza las etiquetas Hn para entender la estructura temática de una página. Una jerarquía coherente ayuda a los motores a identificar los temas principales y secundarios tratados. Más allá del SEO, esto también es una cuestión de accesibilidad: los lectores de pantalla utilizan esta jerarquía para navegar por el contenido.
El mayor beneficio de este análisis es que señala errores de plantilla. Un problema de estructura Hn que se repite en cientos de páginas suele ser un único problema de plantilla que se puede corregir y tiene un gran impacto.
En resumen
Estos tres análisis no reemplazan los controles clásicos de una auditoría técnica. Los complementan. Una vez que los domines, ofrecen una serie de perspectivas que amplían tus ángulos de observación.
El punto más importante a recordar es una realidad que va más allá de estos tres ejemplos: un rastreo no es un objetivo, es una herramienta de diagnóstico. Los datos en bruto no significan nada sin interpretación. El verdadero valor de una auditoría técnica es la capacidad de leer patrones, entender causas y hacer recomendaciones prácticas. Y todo comienza con el hábito de categorizar antes del análisis.
Las imágenes en este artículo fueron creadas con Scouter, un rastreador SEO de código abierto y autohospedado. Está disponible en lokoe.fr/crawler-seo-scouter.






































Comentarios
(8 Comentarios)