
Quando esegui una scansione su un sito web, il primo riflesso è spesso lo stesso: immergersi nell'elenco dei codici HTTP, filtrare gli errori 404, seguire i titoli duplicati e controllare se ogni pagina ha un H1. Queste analisi sono obbligatorie. Costituiscono la base di un audit tecnico serio e nessuno dovrebbe rinunciare a esse.
Tuttavia, la ricchezza di una scansione non si limita a questo. Dietro agli indicatori classici si nascondono analisi meno comuni che offrono una preziosa luce sulla reale salute del sito. In questo articolo vengono presentate tre di esse. Non per sostituire i controlli abituali, ma forse per aggiungere angoli di analisi che non hai ancora utilizzato.
Gli esempi visivi in questo articolo sono stati presi da Scouter, un crawler SEO open source e auto-ospitato. Tuttavia, i principi qui descritti sono validi indipendentemente dallo strumento che utilizzi.
Prima di entrare nel vivo dell'argomento, c'è una premessa.
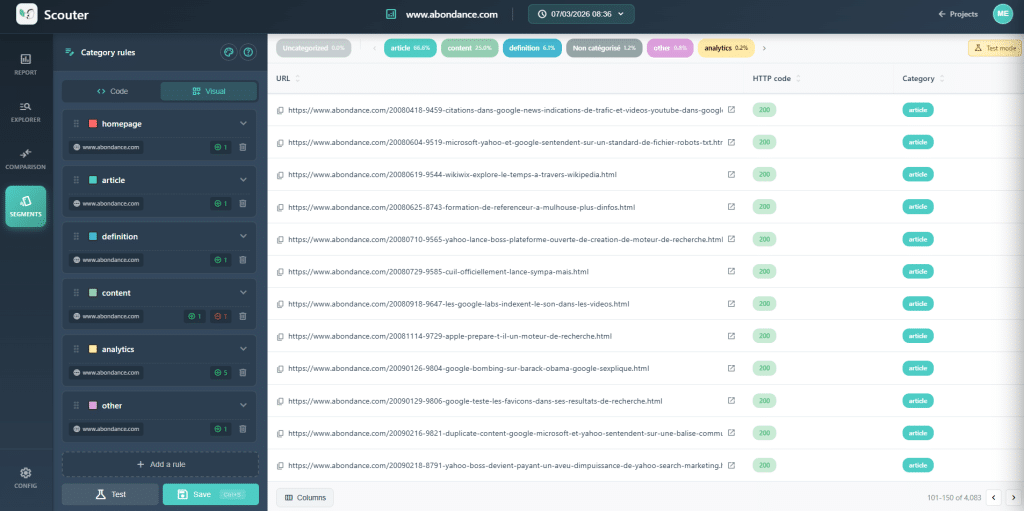
Prima di Qualsiasi Analisi: Categorizza i Tuoi URL
Questo è il movimento che trasforma una scansione grezza in uno strumento diagnostico. Prima di analizzare qualsiasi cosa, il primo passo è raggruppare i tuoi URL secondo un modello tecnico: pagine di prodotto, pagine di categoria, articoli del blog, pagine aziendali, ecc. Senza questa suddivisione, stai lavorando alla cieca.
Perché È Obbligatorio?
Prendiamo un esempio concreto. La tua scansione mostra che c'è un 30% di H1 duplicati su tutto il sito. Questo numero è spaventoso. Tuttavia, nella sua forma attuale, non dice nulla sulla causa del problema.
Ora, suddividi questi dati per categoria. Scoprirai che il contenuto duplicato è ampiamente concentrato sulle pagine di prodotto. L'ipotesi si fa chiara: le varianti (colore, taglia) producono lo stesso H1 perché la variante non è presente nel titolo. Anche la proposta è chiara: modificare la regola di creazione dell'H1 del prodotto per aggiungere la qualità della variante (ad esempio, il colore del prodotto).
Nel modello dell'articolo, lo stesso sintomo potrebbe avere una causa completamente diversa: marcatura scorretta del modello, H1 codificato in modo fisso, campo editoriale configurato in modo errato. Anche la proposta sarà diversa.
Logica da Ricordare: Riconosci l'Anomalia → Suddividi per Modello → Osserva gli Esempi → Comprendi il Modello → Crea una Proposta Mirata.
Questo processo di categorizzazione dà significato a tutte le analisi successive. Pensalo come un filtro che applichi ai tuoi dati, consentendoti di passare da un'osservazione generale a una comprensione più sottile.
1. Profondità della Scansione: Diagnostica Velocemente la Tua Architettura
Tra i dati ottenuti durante una scansione, il livello di profondità delle pagine è probabilmente il più significativo. Molti lo ignorano, accontentandosi di controllare che le pagine importanti non siano "troppo profonde". Questo significa perdere l'essenziale.
Di Cosa Stiamo Parlando?
Il livello di profondità di una pagina si riferisce al numero minimo di collegamenti che devono essere seguiti per accedervi dalla homepage. Questo è il percorso più breve, non un qualsiasi percorso. Viene spesso semplificato utilizzando il termine "click", ma ciò che conta sono i collegamenti. La homepage è al livello 0, le pagine a cui collega direttamente sono al livello 1 e così via.
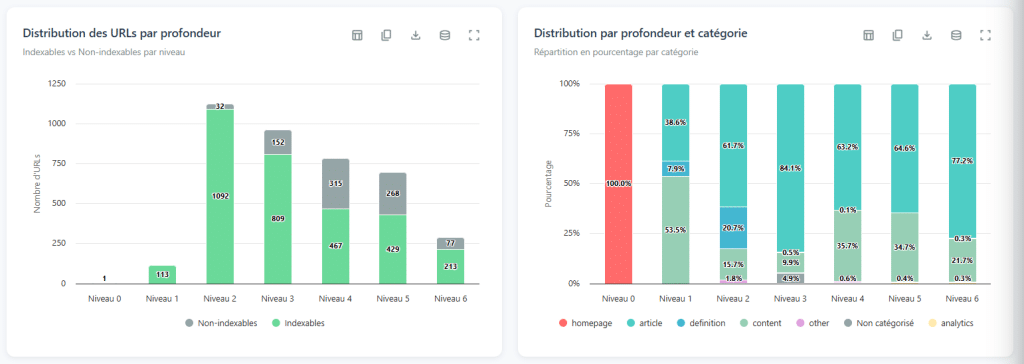
Leggere la Curva di Profondità
Il punto di interesse in questa analisi non è nei numeri grezzi, ma nell'esaminare la forma della curva di distribuzione. Solo guardandola, puoi diagnosticare grandi problemi strutturali.
Una curva piatta, quando si estende su decine di livelli (con poche pagine in ogni livello): questo è quasi sicuramente un segnale di paginazione lineare. Il sito consente solo di passare da una pagina all'altra; pagina 1, pagina 2, pagina 3… Il browser deve superare ogni fase per raggiungere i contenuti alla fine dell'indice. Risultato: le pagine più profonde diventano quasi inaccessibili.
Una curva a due picchi (sale, scende, poi risale): questo è un segnale quasi orfano. Il primo picco rappresenta il cuore di un sito ben collegato. Il secondo picco rappresenta una serie di pagine collegate all'altra solo da pochi collegamenti in profondità. Se interrompi queste rare connessioni, questa parte del sito diventa completamente isolata. Risultato: poca accessibilità, poca autorità trasferita.
Troppa profondità, poche pagine (ad esempio, cinque livelli e solo cinquanta pagine): qui c'è un problema di efficienza nei collegamenti interni. Queste pagine devono essere accessibili con molte meno clic.
Dimentica la Regola dei "3 Clic"
La famosa regola "tutto deve essere accessibile in 3 clic" è una leggenda persistente. Immagina di applicarla ad Amazon o a qualsiasi sito di grande scala: è semplicemente impossibile. È più utile pensare in termini di proporzioni piuttosto che attenersi a un numero specifico.
Per valutare se la tua profondità è coerente, prendi una semplice base teorica. Supponi che la homepage (livello 0) scopra circa 100 pagine. Poi, considera che ogni nuova pagina scopre in media altre 10 pagine. Risultato: circa 100 pagine a livello 1, 1.000 pagine a livello 2, 10.000 pagine a livello 3.
Il tuo obiettivo non è aderire esattamente a questo modello, ma confrontare la tua reale profondità con questa base teorica. Se il tuo sito ha 500 pagine e hai già 5 livelli di profondità, dovresti esaminare i collegamenti perché teoricamente puoi coprire queste pagine con solo 2 livelli di profondità.
2. Copia Vicina: Copia Invisibile
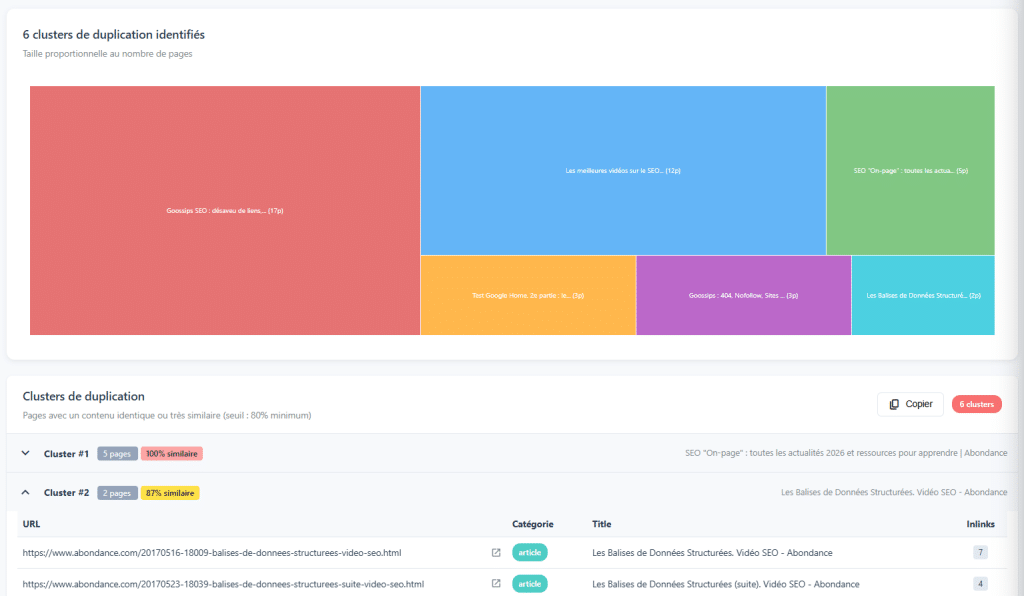
Quando si tratta di copia di contenuti, tutti conoscono DUST (URL duplicato, stesso testo): due URL diversi che presentano esattamente lo stesso contenuto. È facile da rilevare e spesso correggerlo è semplice. Tuttavia, esiste una forma di copia più subdola: copia vicina.
Pagine Estremamente Simili
La copia vicina si riferisce a pagine il cui contenuto è molto simile, sebbene non identico. Cambiare alcune parole, aggiungere o rimuovere un paragrafo, una leggera riformulazione... ma sostanzialmente contenuti simili. Gli algoritmi di rilevamento (come Simhash, utilizzato da molti motori di ricerca) identificano queste somiglianze confrontando le impronte dei contenuti.
Queste pagine rappresentano un vero problema. Distribuiscono l'autorità tra più URL, invece di concentrarla in un unico posto. Si consumano a vicenda nel posizionamento. E inviano a Google un segnale di contenuto a basso valore. In alcuni casi, la decisione corretta è quella di unire questi contenuti in una singola pagina più ricca e pertinente.
Attenzione ai Falsi Positivi
Questo è un punto di attenzione importante: qualsiasi somiglianza di contenuto non è necessariamente un problema.
Se gestisci un sito in molte lingue e hai versioni en-GB e en-US, è del tutto normale che queste pagine siano quasi identiche. Si rivolgono a mercati diversi. La stessa logica vale per le pagine localizzate geograficamente: "idraulico a Parigi" e "idraulico a Lione" condividono spesso lo stesso modello con piccole variazioni, ed è intenzionale. La copia vicina è un segnale da indagare, non un giudizio automatico. È l'analisi manuale sullo sfondo a determinare se si tratta di un vero problema o di un falso positivo legato al contesto del sito.
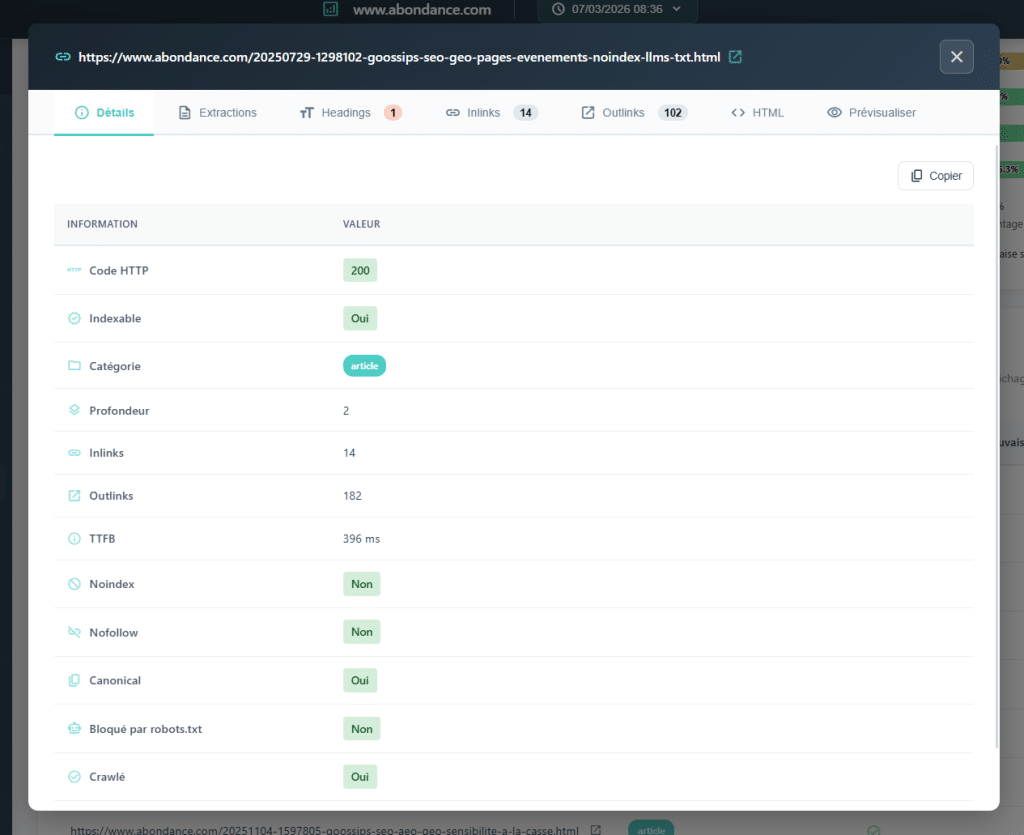
3. Struttura Hn: H2, H3, H4 sono davvero Ordinati?
Quando si controlla il markup di un sito, il riflesso è controllare l'H1: è presente? È unico? È pertinente? Questo è buono. Tuttavia, la struttura del titolo di una pagina non è limitata solo all'H1. È tutta la gerarchia che organizza il contenuto e aiuta i motori a comprendere il contenuto (da H1 a H6).
Problemi Invisibili
Analizzare la struttura Hn su scala di scansione consente di identificare anomalie sistemiche che non emergono semplicemente controllando l'H1.
Salti nei livelli: un passaggio diretto da H1 a H3 in una pagina, senza il livello intermedio H2. Questo rappresenta una rottura nella logica gerarchica del documento. Mancanza di H1, presenza di H2, incoerenze strutturali comuni. Strutture completamente disordinate, segno di un contenuto contrassegnato senza un modello o un metodo ben progettato.
Inoltre, la duplicazione massiccia di H2 è un sintomo che spesso non è visibile quando si guarda solo agli H1. Questo può far emergere un problema di modello: blocchi riutilizzati da una pagina all'altra (widget, moduli della barra laterale, intestazioni contrassegnate come H2…) inquinano la struttura dei titoli di ogni pagina.
Perché è Importante?
Google utilizza i tag Hn per comprendere la struttura tematica di una pagina. Una gerarchia coerente aiuta i motori a identificare i temi principali e secondari trattati. Oltre alla SEO, questo è anche una questione di accessibilità: i lettori di schermo utilizzano questa gerarchia per navigare nel contenuto.
Il maggiore vantaggio di questa analisi è segnalare gli errori di modello. Un problema di struttura Hn ripetuto su centinaia di pagine è spesso un problema di modello da correggere e ha un grande impatto.
In Sintesi
Queste tre analisi non sostituiscono i controlli classici di un audit tecnico. Li completano. Una volta che si diventa esperti, offrono una serie di prospettive che ampliano i vostri angoli di osservazione.
Il punto più importante da ricordare è una verità che va oltre questi tre esempi: una scansione non è un obiettivo, è uno strumento diagnostico. I dati grezzi non significano nulla senza interpretazione. Il vero valore di un audit tecnico è la capacità di leggere i modelli, comprendere le cause e fornire raccomandazioni praticabili. E tutto inizia con l'abitudine di categorizzare prima dell'analisi.
Le immagini in questo articolo sono state create con Scouter, un crawler SEO open source e self-hosted. È disponibile su lokoe.fr/crawler-seo-scouter.






































Commenti
(8 Commenti)