OpenAI, le 4 mars, a modifié son modèle par défaut, réduisant de cinq fois le nombre de sites web référencés par réponse, et cela ne s'est jamais rétabli. Cependant, cette baisse n'est qu'une partie de l'histoire. Nous avons également réalisé l'ingénierie inverse des outils de recherche internes de ChatGPT, mené une expérience honeypot, reconfiguré le client système et lancé une nouvelle version de notre plugin ChatGPT Search Capture.
Que s'est-il passé ?
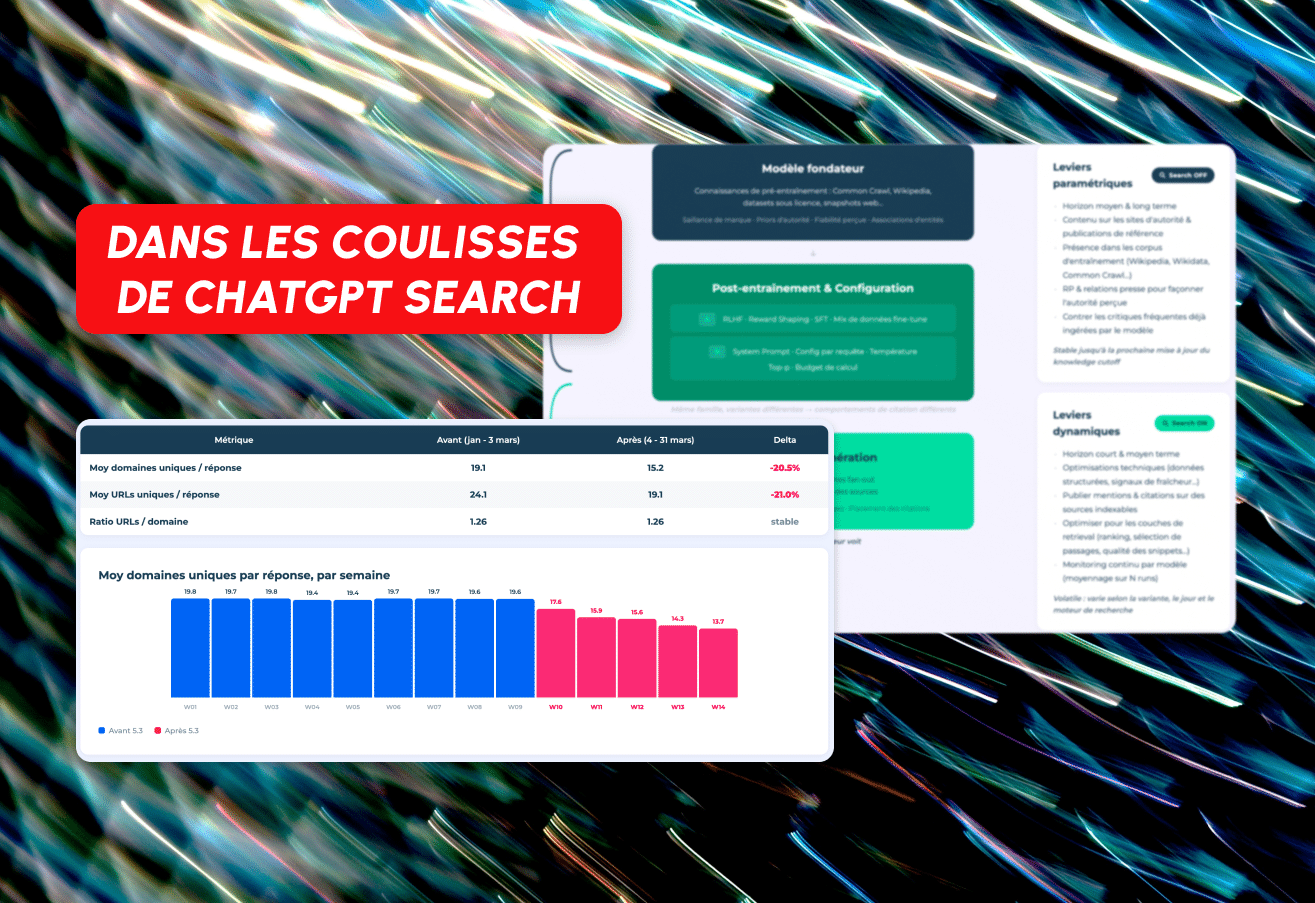
Le 4 mars 2026, ChatGPT a changé son modèle par défaut de GPT-4o/5.2 à GPT-5.3 Instant. En conséquence, le nombre moyen de domaines uniques référencés par réponse est tombé de 19,1 à 15,2, ce qui représente une baisse de plus de 20 %. Le nombre d'URL uniques par réponse a également suivi la même tendance, passant de 24,1 à 19,1.
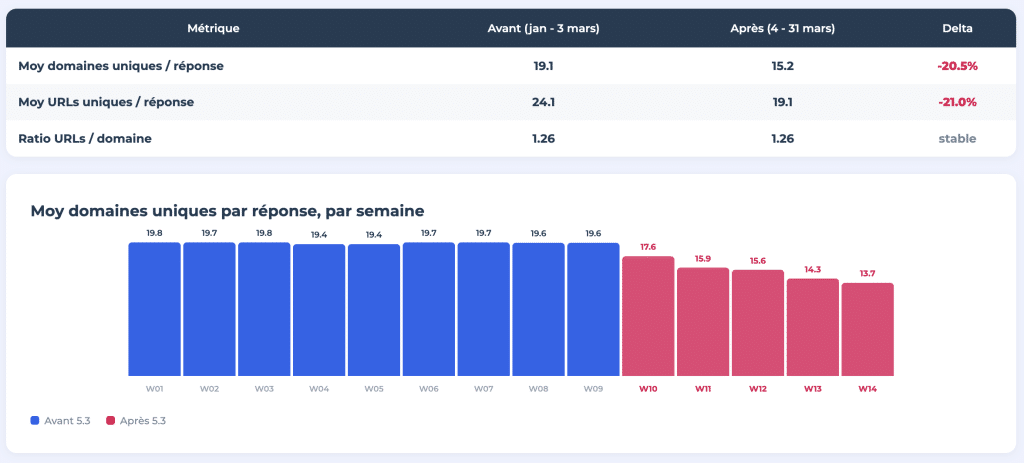
Nous avons suivi 400 requêtes par jour pendant 14 semaines, en nous basant sur les données de suivi fournies par Meteoria. Tous les résultats ont été publiés sous la forme d'une étude interactive en huit parties sur think.resoneo.com/chatgpt/5.3-5.4/.
Pourquoi est-ce important ?
ChatGPT compte 900 millions d'utilisateurs actifs par semaine. Le champ de référence dans chaque réponse n'a pas changé, mais moins de sites web partagent ce champ. C'est le même gâteau, mais avec moins de parts. Cela reflète probablement un changement structurel vers des sources ayant une autorité plus élevée, mais cela signifie également globalement moins de gagnants. Les sites qui ne peuvent pas passer perdent un champ de visibilité qui était auparavant accessible.
L'Effet Bigfoot
Nous avons nommé ce phénomène en référence à la "mise à jour Bigfoot" définie par le Dr. Pete (de Moz) en 2013 ; à l'époque, Google permettait parfois à un seul domaine de couvrir toute la première page...
ChatGPT reçoit maintenant moins de domaines par réponse, mais le ratio d'URL par domaine est resté stable à 1,26. La profondeur de recherche par domaine n'a pas changé. Ce qui a changé, c'est le nombre de sites web différents présents sur la table.
GPT-5.4 Thinking accentue encore cette concentration. Le modèle utilise des opérateurs site: pour restreindre les recherches à des domaines fiables et distribue généralement plus de 10 "requêtes de fan-out" par réponse, chacune se concentrant sur une source spécifique.
L'analyse indépendante de Jérôme Salomon (Oncrawl) sur les logs confirme cette tendance. Le volume de crawl du bot ChatGPT-User s'est stabilisé à un niveau plus bas depuis le passage à 5.3. Certaines pages ne sont plus simplement crawled. La raison dépasse les mises à jour du modèle : plus de 90 % des utilisateurs hebdomadaires de ChatGPT utilisent un plan gratuit, et l'expérience par défaut déclenche moins de recherches web, utilise moins de requêtes et produit moins de références.
Comment fonctionne réellement ChatGPT Search ?
Notre étude présente également l'ingénierie inverse du système de recherche interne de ChatGPT, appelée web.run. Avant 5.3, le modèle envoyait des commandes de texte compact séparées par des pipes (fast|query|recency). Après 5.3, il envoie des paramètres typés sous forme d'objets JSON structurés. Cela reflète une architecture différente en termes de formulation et de distribution des opérations du modèle sur le web.
L'outil web a désormais augmenté le nombre d'opérations de 4 à 12 (il y a aussi un système de widget distinct appelé genui). Ici, on trouve des opérations telles que search_query, open, find, click, screenshot, product_query, ainsi que des widgets spécifiques comme le sport, la finance, la météo. GPT-5.4 peut effectuer jusqu'à 10 tours de recherche par réponse, affinant ses requêtes en fonction des résultats précédents. GPT-5.3 Instant se limite généralement à 2 ou 3.
Les traces de Google sont toujours visibles : les marques de suivi Google (strlid) sont visibles dans les URL générées et les correspondances ID-to-token dans SearchAPI révèlent la dépendance à Google et aux fournisseurs de recherche tiers en arrière-plan.
Un Nouveau Type de Fan-out pour les Requêtes de Produits
Nous avons découvert un type de fan-out encore non documenté : browse_rewritten_queries. Cela n'apparaît que dans les requêtes de produits, visible dans 5.4 Instant et dans le code de conversation.
Lorsqu'un utilisateur pose une question comme "les meilleures imprimantes 3D à acheter en 2026", ChatGPT lance d'abord un fan-out de réécriture unique pour générer une liste complète des produits candidats. Ensuite, il lance un fan-out d'achat séparé pour chaque produit individuel, récupérant les caractéristiques, les avis et les prix un par un. Avant 5.3, les recherches de produits étaient regroupées en un seul appel. Maintenant, chaque produit a sa propre commande de récupération.
ChatGPT-User est un Agent de Récupération de Contenu
Notre expérience honeypot a confirmé un détail important. Lorsque ChatGPT navigue sur le web après une recherche au cours d'une conversation, il agit comme un navigateur ChatGPT-User, pas comme OAI-SearchBot. OpenAI définit OAI-SearchBot comme l'agent qui constitue l'index de recherche de ChatGPT, mais en pratique, le modèle s'appuie sur des API de scraping tierces pour obtenir les résultats de recherche, puis envoie ChatGPT-User pour récupérer le contenu réel des URL sélectionnées.
Le Point Aveugle des Namespaces : La Vulnérabilité de ChatGPT
C'est peut-être notre découverte la plus surprenante.
Le suivi a commencé par une ingénierie inverse classique. Nous avons décompilé l'application mobile ChatGPT, analysé le code source du client web et suivi les paquets réseau sur les deux plateformes. Cela nous a donné les noms des outils internes et certaines conventions d'appel. Avec ces éléments précis, nous avons eu l'opportunité de poser les bonnes questions à ChatGPT - et avons découvert que le modèle y répondait sans aucune restriction.
OpenAI a mis en place de vraies protections autour des clients système. Cependant, la couche de configuration des outils internes est en dehors de cela. Les namespaces de ChatGPT, qui sont des groupes d'outils internes que le modèle peut appeler au cours d'une conversation, peuvent être définis librement. Tant que vous évitez les mots "system prompt", le modèle révèle les schémas d'outils, les listes d'opérations, les canaux de sortie et les structures de namespace avec une cohérence parfaite.
Nous avons publié des invites prêtes à être collées que tout le monde peut utiliser pour auditer l'environnement structurel de ChatGPT. Pour vérifier que le modèle imagine ces définitions, nous avons mené une étude participative avec des dizaines d'utilisateurs dans différentes sessions. Chaque participant a reçu exactement les mêmes noms d'outils, les mêmes schémas de paramètres, les mêmes listes d'opérations. Le modèle définit constamment ses propres outils de manière cohérente, donc fiable ^^
Le travail comprend également un client système réorganisé par inférence progressive avec plusieurs informations clés : Reddit, le seul domaine exempt des limites de mots liées au droit d'auteur, une liste détaillée de produits interdits, un "score de détail excessif" de 1 à 10, et un paragraphe complet de politique publicitaire régissant l'affichage des publicités selon le niveau d'abonnement.
Utilisation Pratique : Réalisez Votre Propre Audit de Crawlabilité
La syntaxe web.run que nous avons documentée n'est pas seulement une curiosité technique. Elle fonctionne et ouvre une voie directe pour tester comment ChatGPT interagit avec vos contenus.
Voici un exemple concret. Vous pouvez forcer ChatGPT à rechercher votre domaine et à lire des pages spécifiques, ce que vous pouvez réaliser en collant directement des commandes JSON dans une conversation.
Tout d'abord, lancez une recherche ciblée sur votre site, puis forcez-le à trouver les deux premiers résultats obtenus, puis demandez-lui de renvoyer le titre de chaque page, le sujet principal et 3 à 5 points clés.
Search for this query, then open the first two results and summarize what you find on each page.
Step 1 : Search:
{
search_query: [
{ q: site:abondance.com seo }
],
response_length: short
}
Step 2 : Open the first two results:
{
open: [
{ ref_id: turn0search0 },
{ ref_id: turn0search1 }
]
}
Step 3 : Give me a structured recap of what you found on each URL. For each page: the title, the main topic, and 3-5 key points.Ce que vous obtiendrez, c'est de voir votre contenu à travers les yeux de ChatGPT : ce à quoi il a réellement accès, ce qu'il extrait et comment il interprète vos pages. Si une page n'est pas accessible, s'il retourne un contenu complexe ou s'il ignore complètement vos messages principaux, c'est un signal d'alerte à prendre en compte.
Pour aller plus loin, l'extension Chrome de RESONEO "ChatGPT Search Capture" (V3.3, disponible gratuitement sur le Chrome Web Store) vous permet de visualiser les URL complètes capturées lors de n'importe quelle conversation ChatGPT ; les requêtes de fan-out (sauf pour 5.3 Instant qui s'exécute maintenant côté serveur), les ref_ids et les métadonnées du modèle. Lorsqu'elle est combinée avec les commandes JSON manuelles ci-dessus, vous obtenez un audit de crawlabilité léger mais réalisable qui montre quelles URL ont été récupérées et ce qu'elles ont réellement extrait.
Une Même Famille de Modèles, Différentes Références
GPT-5.2, 5.3 et 5.4 partagent la même date de coupure (août 2025) et appartiennent à la même famille GPT-5. Cependant, la même invite envoyée à chacun génère différentes requêtes de fan-out, obtient différentes sources et renvoie différents passages dans la réponse finale.
Après la pré-formation, plusieurs couches de séparation entrent en jeu : le façonnage des récompenses de RLHF, les données de réglage supervisé, les configurations du client système et les budgets de calcul en inférence. GPT-5.4 Pro reçoit clairement plus de calcul pour "penser plus intensément", ce qui peut à lui seul changer quelles sources sont référencées.
Par conséquent, nous recommandons de tester d'un modèle à l'autre. Une seule invite peut produire des références radicalement différentes selon que l'utilisateur utilise GPT-5.3 Instant, 5.4 Thinking ou 5.4 Extended. Les utilisateurs du plan gratuit peuvent également être discrètement dirigés vers un modèle allégé.
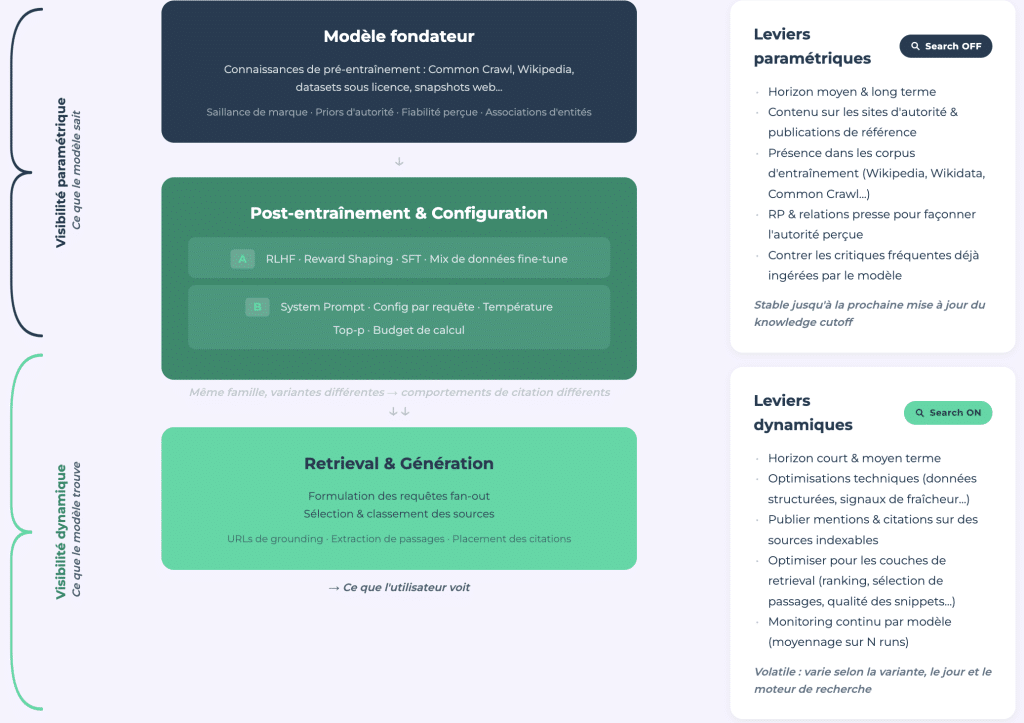
Deux Types de Visibilité AI
Notre étude présente un cadre d'analyse qui distingue entre visibilité paramétrique (ce que le modèle sait grâce à ses données d'entraînement, recherche fermée) et visibilité dynamique (ce qu'il récupère en temps réel, recherche ouverte).
Visibilité Paramétrique : L'E-E-A-T des LLM
La visibilité paramétrique est l'équivalent de l'E-E-A-T pour les grands modèles de langage. C'est une autorité codée à travers des milliards d'exemples d'entraînement et façonnée par la couverture médiatique, la présence sur Wikipedia, d'autres grands sites d'autorité et le corpus d'entraînement général. Elle est stable et mesurable par des audits ponctuels via l'API.
Visibilité Dynamique : Un Domaine Variable
La visibilité dynamique est quant à elle volatile. Elle est influencée par le modèle et nécessite un suivi constant. Elle a une structure plus proche du SEO traditionnel et peut s'effondrer du jour au lendemain avec une mise à jour du modèle ; cela est démontré par l'effet Bigfoot.
Le Lien Entre les Deux
Le lien entre les deux est important. Le modèle formule les requêtes web en se concentrant sur des sources qu'il connaît déjà. Une marque qui n'est pas présente dans la mémoire paramétrique ne sera même pas considérée comme candidate pour la recherche. Ne pas être connu par le modèle signifie être invisible avant même que la recherche ne commence.
Les mises à jour de la date de coupure créent la "Danse de Google" des LLM. Lorsque la date de coupure change, les classements paramétriques sont redistribués collectivement. Cependant, cela ne se produit qu'une fois par an environ, car le réentraînement à cette échelle est extrêmement coûteux. La fenêtre stratégique pour influencer ce que le modèle sait sur votre marque se situe entre deux dates de coupure.
L'Indice d'Autorité de Marque AI de Dan Petrovic (DEJAN) présente un exemple à grande échelle de mesure paramétrique. Notre étude le complète avec un cadre de test plus léger et reproductible ; cela repose sur cinq invites exécutées plusieurs fois pour un audit ponctuel.
Pour Plus d'Informations
L'étude complète (documents d'ingénierie inverse, expérience honeypot, invites d'audit DIY et client système réorganisé) est disponible sur think.resoneo.com/chatgpt/5.3-5.4/.
Un Bref Résumé
ChatGPT Search n'est plus une boîte noire. Cette étude cartographie son architecture interne, jusqu'à la logique de fan-out qui détermine quels domaines sont récupérés et lesquels sont ignorés pour chaque recherche.
La baisse de 20 % du nombre de domaines référencés après le passage à 5.3 montre à quel point le paysage des références peut changer rapidement avec une mise à jour de modèle. Cependant, le problème fondamental est structurel : ChatGPT concentre ses références sur moins de sites web et applique une logique de sélection qui détermine les sources de référence ; cela est façonné par les données d'entraînement, le réglage post-formation et les règles de client système qui varient d'un modèle à l'autre.
Suivre la visibilité dans ChatGPT nécessite de comprendre deux couches distinctes (paramétrique et dynamique), de tester sur plusieurs modèles et de surveiller un système avec des outils internes documentables ; cependant, le comportement de ce système peut changer du jour au lendemain.
L'étude complète fournit les données, la méthodologie et les outils nécessaires pour commencer.






































Commentaires
(10 Commentaires)