OpenAI hat am 4. März das Standardmodell geändert, wodurch die Anzahl der verwiesenen Websites pro Antwort um ein Fünftel gesenkt wurde und sich nie wieder erholen konnte. Doch dieser Rückgang ist nur ein Teil der Geschichte. Gleichzeitig haben wir die internen Suchwerkzeuge von ChatGPT rückentwickelt, ein Honeypot-Erlebnis durchgeführt, den Systemclient neu konfiguriert und eine neue Version unseres ChatGPT-Such-Capture-Plugins veröffentlicht.
Was ist passiert?
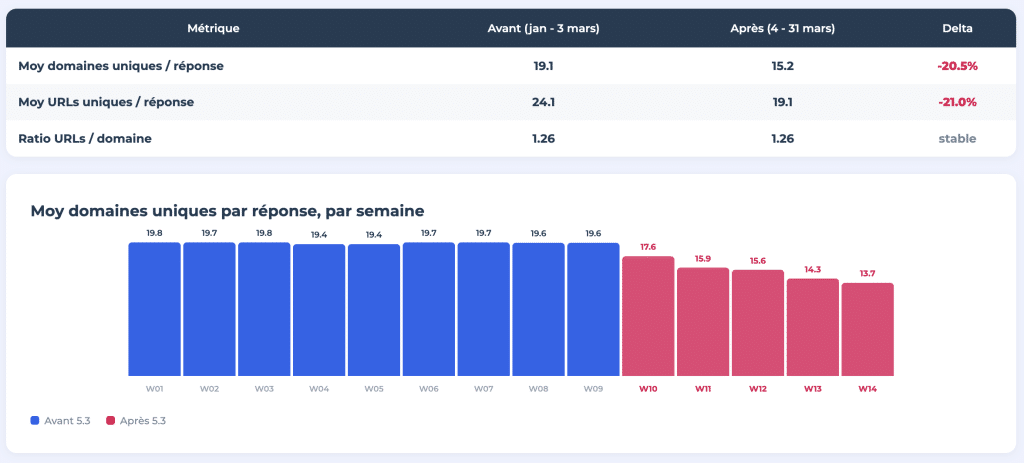
Am 4. März 2026 wechselte ChatGPT sein Standardmodell von GPT-4o/5.2 zu GPT-5.3 Instant. Infolgedessen sank die durchschnittliche Anzahl der verwiesenen einzigartigen Domains pro Antwort von 19,1 auf 15,2, was mehr als einem Rückgang von 20 % entspricht. Auch die Anzahl der einzigartigen URLs pro Antwort folgte demselben Trend und fiel von 24,1 auf 19,1.
Wir haben 14 Wochen lang täglich 400 Anfragen verfolgt und uns auf die von Meteoria bereitgestellten Überwachungsdaten gestützt. Alle Ergebnisse wurden als achtteilige interaktive Studie unter think.resoneo.com/chatgpt/5.3-5.4/ veröffentlicht.
Warum ist das wichtig?
ChatGPT hat wöchentlich 900 Millionen aktive Nutzer. Der Referenzbereich innerhalb jeder Antwort hat sich nicht verändert, aber weniger Websites teilen diesen Bereich. Der gleiche Kuchen, aber mit weniger Stücken. Dies spiegelt wahrscheinlich eine strukturelle Verschiebung hin zu Quellen mit höherer Autorität wider, bedeutet aber auch insgesamt weniger Gewinner. Websites, die die Auswahl nicht bestehen, verlieren einen Sichtbarkeitsbereich, der zuvor zugänglich war.
Bigfoot-Effekt
Wir haben dieses Phänomen benannt, indem wir auf das 2013 von Dr. Pete (von Moz) definierte "Bigfoot-Update" verwiesen; damals erlaubte Google manchmal, dass eine einzige Domain die gesamte erste Seite einnahm...
ChatGPT erhält jetzt weniger Platz pro Antwort, aber das Verhältnis von URLs pro Domain blieb mit 1,26 konstant. Die Crawltiefe pro Domain hat sich nicht verändert. Was sich geändert hat, ist die Anzahl der verschiedenen Websites, die auf dem Tisch stehen.
GPT-5.4 Thinking verstärkt diese Konzentration weiter. Das Modell verwendet site:-Operatoren, um die Suchanfragen auf vertrauenswürdige Domains zu beschränken und verteilt in der Regel mehr als 10 "Fan-out-Anfragen" pro Antwort, wobei jede auf eine bestimmte Quelle fokussiert ist.
Die unabhängige Analyse von Jérôme Salomon (Oncrawl) über Logs bestätigt diesen Trend. Das Crawling-Volumen des ChatGPT-User-Bots hat sich seit dem Übergang zu 5.3 auf einem niedrigeren Niveau stabilisiert. Einige Seiten werden jetzt einfach nicht mehr gecrawlt. Der Grund geht über Modellaktualisierungen hinaus: Mehr als 90 % der wöchentlichen Nutzer von ChatGPT verwenden einen kostenlosen Plan, und das Standarderlebnis löst weniger Websuchen aus, verwendet weniger Anfragen und produziert weniger Referenzen.
Wie funktioniert ChatGPT-Suche wirklich?
Unsere Studie zeigt auch die Rückentwicklung des internen Suchsystems von ChatGPT, das als web.run bezeichnet wird. Vor 5.3 sendete das Modell kompakte Textbefehle, die durch Pipes (fast|query|recency) getrennt waren. Nach 5.3 sendet es typisierte Parameter mit strukturierten JSON-Objekten. Dies spiegelt mehr als nur eine einfache Formatänderung wider. Es zeigt eine andere Architektur in der Art und Weise, wie das Modell Operationen im Web formuliert und verteilt.
Das Web-Tool hat die Anzahl der Operationen von zuvor 4 auf 12 erhöht (es gibt auch ein separates Widget-System namens genui). Hier finden sich Operationen wie search_query, open, find, click, screenshot, product_query sowie spezielle Widgets für Sport, Finanzen, Wetter usw. GPT-5.4 kann für jede Antwort 5 bis 10 Recherche-Runden durchführen und die Anfragen basierend auf vorherigen Ergebnissen verfeinern. GPT-5.3 Instant begnügt sich normalerweise mit 2 oder 3.
Google-Spuren sind immer noch sichtbar: Google-Tracking-IDs (strlid) sind in den generierten URLs sichtbar, und die ID-to-Token-Mappings in der SearchAPI zeigen die Abhängigkeit von Google und Drittanbietersuchanbietern im Hintergrund auf.
Eine neue Art von Fan-out für Produktanfragen
Wir haben eine bisher nicht dokumentierte Art von Fan-out entdeckt: browse_rewritten_queries. Dies ist nur bei Produktanfragen sichtbar und erscheint in 5.4 Instant sowie im Gesprächscode.
Wenn ein Nutzer eine Frage wie "Die besten 3D-Drucker zum Kauf im Jahr 2026" stellt, startet ChatGPT zuerst einen einzelnen Rewrite-Fan-out, um eine vollständige Liste der Kandidatenprodukte zu erstellen. Danach startet es für jedes einzelne Produkt einen separaten Shopping-Fan-out und ruft die Eigenschaften, Bewertungen und Preise einzeln ab. Vor 5.3 wurden Produktanfragen in einem einzigen Aufruf zusammengefasst. Jetzt hat jedes Produkt seinen eigenen Abrufbefehl.
ChatGPT-User ist ein Inhaltserfassungsagent
Unser Honeypot-Erlebnis hat ein wichtiges Detail bestätigt. Wenn ChatGPT während eines Gesprächs im Internet surft, nachdem eine Suche durchgeführt wurde, ist es der ChatGPT-User Browser, der Inhalte von Seiten abruft, nicht der OAI-SearchBot. OpenAI definiert den OAI-SearchBot als den Agenten, der den Suchindex von ChatGPT erstellt, aber in der Praxis verlässt sich das Modell auf Drittanbieter-Scraping-APIs, um Suchergebnisse zu erhalten, und schickt dann den ChatGPT-User, um den tatsächlichen Inhalt der ausgewählten URLs abzurufen.
Der blinde Fleck der Namespaces: Die Schwäche von ChatGPT
Dies ist vielleicht unsere überraschendste Entdeckung.
Das Tracking begann mit klassischer Rückentwicklung. Wir haben die ChatGPT-Mobile-App dekompiliert, den Quellcode des Webclients zerlegt und Netzwerkpakete auf beiden Plattformen überwacht. Dies gab uns die Namen der internen Werkzeuge und einige Aufrufkonventionen. Mit diesen genauen Elementen hatten wir die Möglichkeit, ChatGPT die richtigen Fragen zu stellen - und entdeckten, dass das Modell ohne Einschränkungen darauf antwortete.
OpenAI hat echte Schutzmaßnahmen um die Systemclients herum aufgebaut. Aber die Konfigurationsebene der internen Werkzeuge ist davon ausgeschlossen. Die Namespaces von ChatGPT, die Gruppen interner Werkzeuge sind, die das Modell während eines Gesprächs aufrufen kann, sind frei definierbar. Solange Sie den Begriff "Systemprompt" vermeiden, offenbart das Modell die Werkzeugdiagramme, die Prozesslisten, die Ausgabekanäle und die Struktur der Namespaces mit bemerkenswerter Konsistenz.
Wir haben vorgefertigte Prompts veröffentlicht, die jeder in ChatGPT einfügen kann, um die strukturelle Umgebung zu überprüfen. Um zu bestätigen, dass das Modell diese Definitionen tatsächlich imaginiert, haben wir in verschiedenen Sitzungen eine partizipative Studie mit Dutzenden von Nutzern durchgeführt. Jeder Teilnehmer erhielt genau die gleichen Werkzeugnamen, die gleichen Parameterschemata, die gleichen Prozesslisten. Das Modell definiert seine Werkzeuge konstant konsistent, daher ist es zuverlässig ^^
Die Studie umfasst auch einen schrittweisen rekonstruierten Systemclient mit mehreren wichtigen Informationen: Reddit, die einzige Domain, die von den urheberrechtlichen Wortgrenzen ausgenommen ist, eine detaillierte Liste verbotener Produkte, eine "Überdetailierungsbewertung" von 1 bis 10 und einen vollständigen Absatz zur Werberichtlinien, der die Anzeige von Werbung je nach Abonnementstufe steuert.
Praktische Anwendung: Führen Sie Ihre eigene Crawlability-Überprüfung durch
Die dokumentierte web.run-Syntax ist nicht nur eine technische Neugier. Sie funktioniert und eröffnet einen direkten Weg, um zu testen, wie ChatGPT mit Ihren Inhalten interagiert.
Hier ist ein konkretes Beispiel. Sie können ChatGPT zwingen, Ihre Domain zu durchsuchen und bestimmte Seiten zu lesen, indem Sie direkt in ein Gespräch JSON-Befehle einfügen.
Starten Sie zunächst eine gezielte Suche auf Ihrer Website, dann zwingen Sie es, die ersten beiden Ergebnisse zu finden, und bitten Sie es anschließend, den Titel, das Hauptthema und 3-5 Hauptpunkte von jeder Seite zurückzusenden.
Search for this query, then open the first two results and summarize what you find on each page.
Step 1 : Search:
{
search_query: [
{ q: site:abondance.com seo }
],
response_length: short
}
Step 2 : Open the first two results:
{
open: [
{ ref_id: turn0search0 },
{ ref_id: turn0search1 }
]
}
Step 3 : Give me a structured recap of what you found on each URL. For each page: the title, the main topic, and 3-5 key points.Was Sie erhalten werden, ist die Sicht auf Ihre Inhalte aus der Perspektive von ChatGPT: was es tatsächlich erreichen kann, was es extrahiert und wie es Ihre Seiten interpretiert. Wenn es auf eine Seite nicht zugreifen kann, komplexen Inhalt zurückgibt oder Ihre Hauptbotschaften vollständig ignoriert, ist das ein Signal, das Handlungsbedarf erfordert.
Um weiterzugehen, ermöglicht die Chrome-Erweiterung von RESONEO "ChatGPT Search Capture" (V3.3, kostenlos im Chrome Web Store) die Visualisierung der vollständigen URLs, die während jedes ChatGPT-Gesprächs erfasst werden; Fan-out-Anfragen (außer 5.3 Instant, das jetzt serverseitig ausgeführt wird), ref_ids und die Metadaten des Modells. Kombiniert mit den manuellen JSON-Befehlen oben erhalten Sie eine leichte, aber umsetzbare Crawlability-Überprüfung, die zeigt, welche URLs abgerufen wurden und was tatsächlich extrahiert wurde.
Die gleiche Modellfamilie, unterschiedliche Referenzen
GPT-5.2, 5.3 und 5.4 haben dasselbe Schnittdatum (August 2025) und gehören zur gleichen GPT-5-Familie. Dennoch erzeugt dasselbe Prompt, das an jede von ihnen gesendet wird, unterschiedliche Fan-out-Anfragen, erhält unterschiedliche Quellen und bringt unterschiedliche Passagen in der endgültigen Antwort zurück.
Nach dem Pre-Training treten mehrere Schichten der Divergenz in Kraft: Die Belohnungsformung von RLHF, die Daten für die überwachte Feinabstimmung, die Konfigurationen des Systemclients und die Berechnungsbudgets in der Inferenz. GPT-5.4 Pro erhält eindeutig mehr Berechnungen, um "intensiver zu denken", und das allein kann beeinflussen, welche Quellen referenziert werden.
Deshalb empfehlen wir, von Modell zu Modell zu testen. Ein einzelnes Prompt kann je nachdem, ob der Nutzer GPT-5.3 Instant, 5.4 Thinking oder 5.4 Extended verwendet, grundlegend unterschiedliche Referenzen erzeugen. Nutzer des kostenlosen Plans können auch stillschweigend auf ein abgeschwächtes Modell umgeleitet werden.
Zwei Arten von KI-Sichtbarkeit
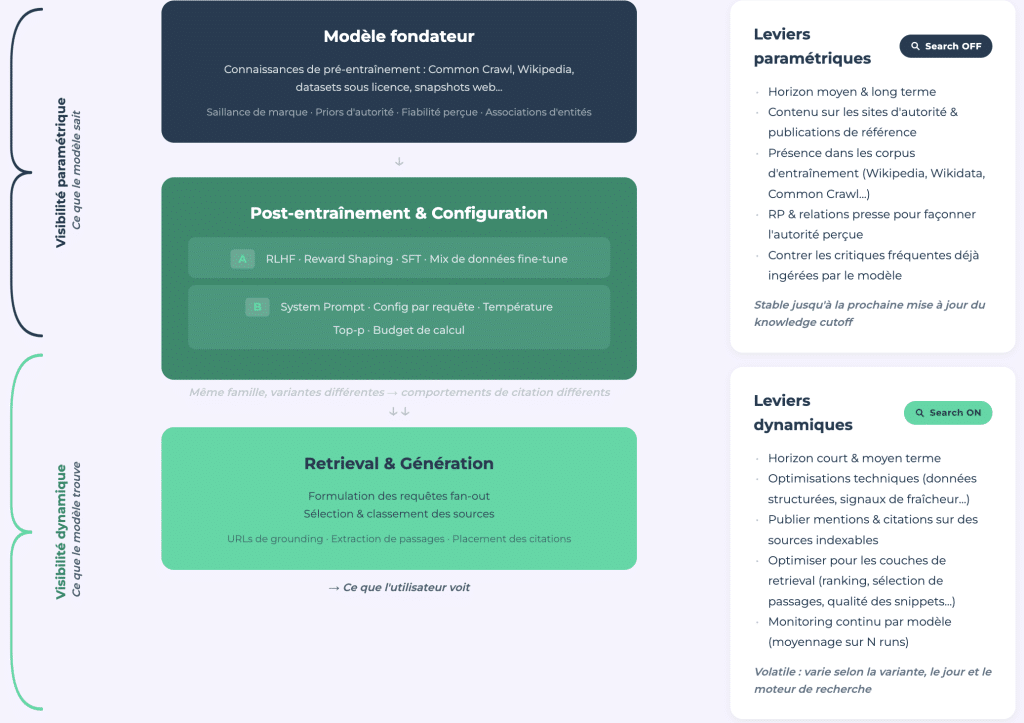
Unsere Studie bietet einen Analyserahmen, der zwischen parametrischer Sichtbarkeit (was das Modell aufgrund seiner Trainingsdaten weiß, Suche geschlossen) und dynamischer Sichtbarkeit (was es in Echtzeit zurückholt, Suche offen) unterscheidet.
Parametrische Sichtbarkeit: E-E-A-T der LLMs
Parametrische Sichtbarkeit ist das Äquivalent von E-E-A-T für große Sprachmodelle. Es ist die Autorität, die durch Milliarden von Trainingsbeispielen kodiert ist und wird durch Medienberichterstattung, Präsenz auf Wikipedia, andere große Autoritätsseiten und das allgemeine Trainingskorpus geformt. Stabil und messbar durch einmalige Audits über die API.
Dynamische Sichtbarkeit: Ein variabler Bereich
Dynamische Sichtbarkeit hingegen ist volatil. Sie wird vom Modell beeinflusst und erfordert kontinuierliches Monitoring. Sie hat eine Struktur, die traditioneller SEO ähnelt und kann über Nacht durch ein Modell-Update zusammenbrechen; dies wird durch den Bigfoot-Effekt veranschaulicht.
Die Verbindung zwischen beiden
Die Verbindung zwischen beiden ist wichtig. Das Modell formuliert Webanfragen, indem es sich auf Quellen konzentriert, die es zuvor kannte. Eine Marke, die nicht im parametrischen Gedächtnis vorhanden ist, wird nicht einmal als Kandidat für die Suche in Betracht gezogen. Unbekannt zu sein bedeutet, unsichtbar zu sein, bevor die Suche beginnt.
Updates am Schnittdatum erzeugen den "Google-Tanz" der LLMs. Wenn sich das Schnittdatum ändert, werden parametrische Rankings kollektiv neu verteilt. Dies geschieht jedoch nur etwa einmal im Jahr, da das erneute Training in diesem Maßstab sehr kostspielig ist. Das strategische Fenster, um zu beeinflussen, was das Modell über Ihre Marke weiß, liegt zwischen zwei Schnittdaten.
Der AI-Markenautoritätsindex von Dan Petrovic (DEJAN) bietet ein großangelegtes Beispiel für parametrische Messungen. Unsere Studie ergänzt dies mit einem leichteren und reproduzierbaren Testrahmen, der auf fünf Prompts basiert, die mehrere Male für eine einmalige Überprüfung durchgeführt werden.
Für weitere Informationen
Die vollständige Studie (Rückentwicklungsdokumente, Honeypot-Erfahrung, DIY-Audit-Prompts und rekonstruierten Systemclient) ist unter think.resoneo.com/chatgpt/5.3-5.4/ verfügbar.
Eine kurze Zusammenfassung
ChatGPT-Suche ist jetzt kein schwarzer Kasten mehr. Diese Studie kartiert die interne Architektur bis zur Fan-out-Logik, die bestimmt, welche Domains bei jeder Suche zurückgeholt werden und welche ignoriert werden.
Der Rückgang von 20 % in der Anzahl der verwiesenen Domains nach dem Übergang zu 5.3 zeigt, wie schnell sich die Referenzlandschaft mit einem Modell-Update ändern kann. Doch das zugrunde liegende Problem ist strukturell: ChatGPT konzentriert seine Referenzen auf weniger Websites und wendet eine Auswahllogik an, die die Referenzquellen bestimmt; dies wird durch Trainingsdaten, Feinabstimmung nach dem Training und von Modell zu Modell variierende Systemclient-Regeln geformt.
Die Verfolgung der Sichtbarkeit in ChatGPT erfordert das Verständnis von zwei separaten Schichten (parametrisch und dynamisch), das Testen in mehreren Modellen und das Monitoring eines Systems mit dokumentierbaren internen Werkzeugen; jedoch kann sich das Verhalten dieses Systems über Nacht ändern.
Die vollständige Studie bietet die Daten, Methodologie und Werkzeuge, die Sie benötigen, um zu beginnen.






































Kommentare
(10 Kommentare)