OpenAI, il 4 marzo, ha cambiato il modello predefinito, riducendo il numero di siti web citati per ogni risposta di un quinto, e non si è mai più ripreso. Tuttavia, questo calo è solo una parte della storia. Abbiamo anche ingegnerizzato inversamente gli strumenti di scansione interni di ChatGPT, realizzato un'esperienza honeypot, riconfigurato il client di sistema e rilasciato una nuova versione del nostro plugin ChatGPT Search Capture.
Cosa è Successo?
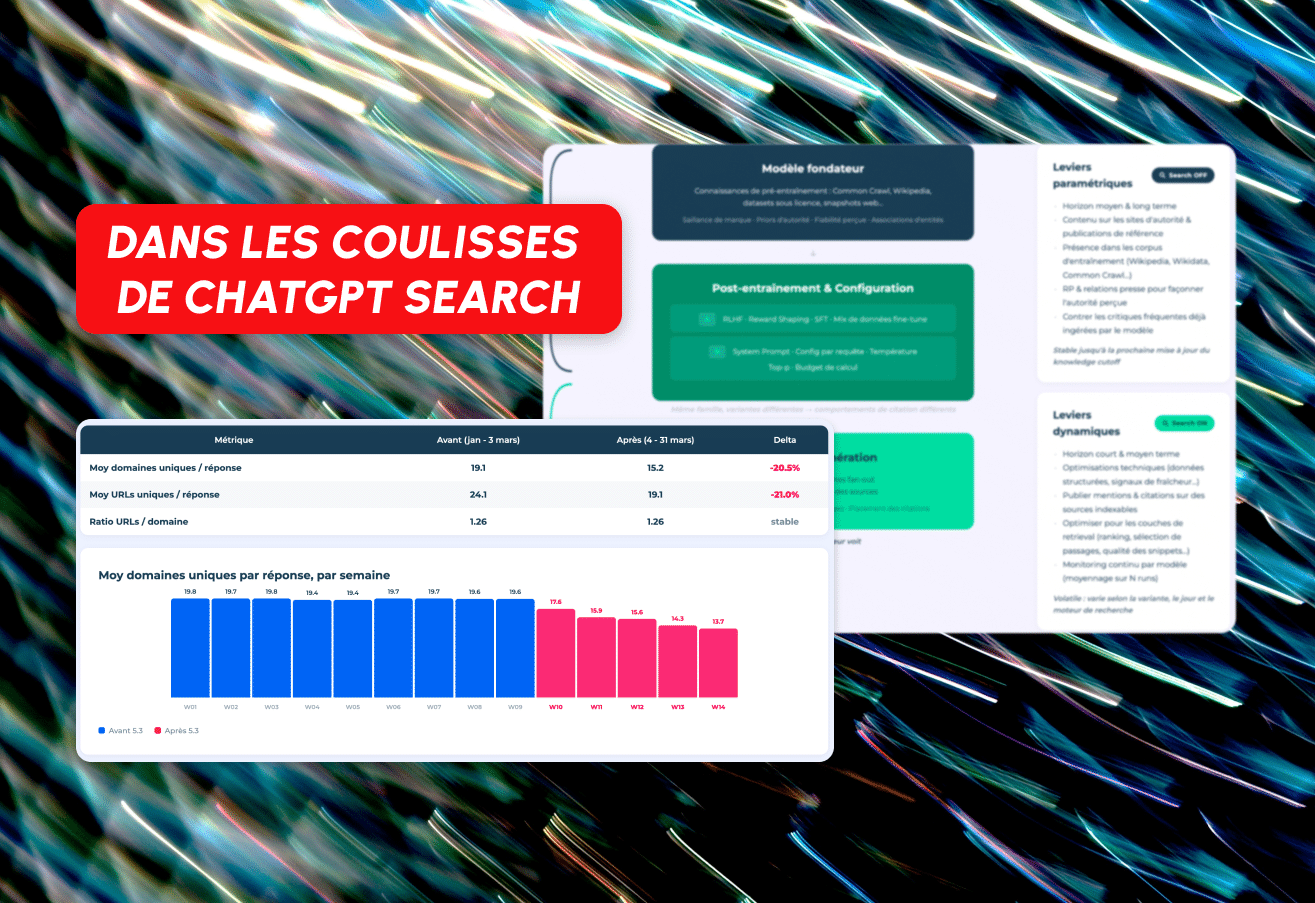
Il 4 marzo 2026, ChatGPT ha cambiato il suo modello predefinito da GPT-4o/5.2 a GPT-5.3 Instant. Di conseguenza, il numero medio di domini unici citati per risposta è sceso da 19,1 a 15,2, il che significa una riduzione di oltre il 20%. Anche il numero di URL unici per risposta ha seguito lo stesso percorso, scendendo da 24,1 a 19,1.
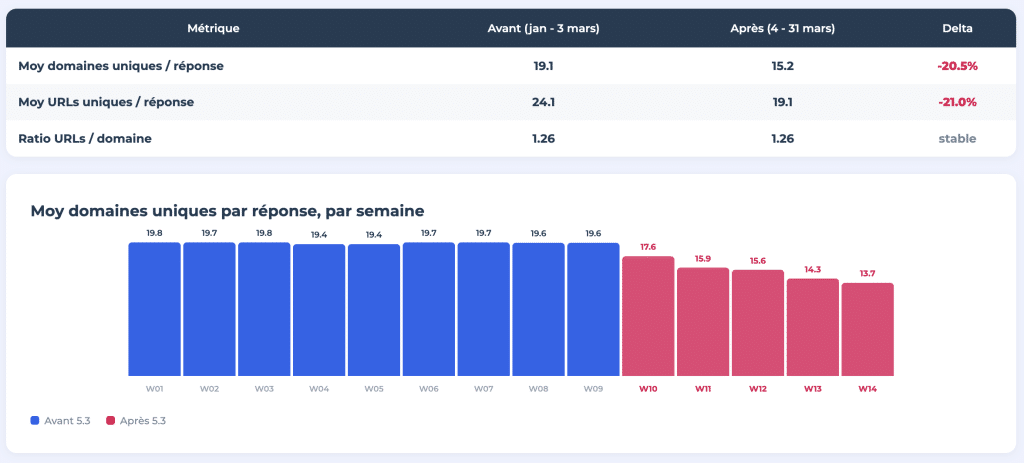
Per 14 settimane, abbiamo monitorato 400 richieste al giorno, basandoci sui dati di monitoraggio forniti da Meteoria. Tutti i risultati sono stati pubblicati come uno studio interattivo in otto parti all'indirizzo think.resoneo.com/chatgpt/5.3-5.4/.
Perché è Importante?
ChatGPT ha 900 milioni di utenti attivi a settimana. L'area di citazione all'interno di ogni risposta non è cambiata, ma meno siti web condividono quest'area. La stessa torta, ma con meno fette. Questo riflette probabilmente uno spostamento strutturale verso fonti con maggiore autorità, ma significa anche meno vincitori in generale. I siti che non riescono a superare la selezione stanno perdendo un'area di visibilità che era precedentemente accessibile.
Effetto Bigfoot
Abbiamo chiamato questo fenomeno in riferimento all'"aggiornamento Bigfoot" definito nel 2013 dal Dr. Pete (di Moz); all'epoca Google permetteva a volte a un singolo dominio di occupare l'intera prima pagina...
ChatGPT ora riceve meno domini per risposta, ma il rapporto URL per dominio è rimasto fisso a 1,26. La profondità di scansione per dominio non è cambiata. Ciò che è cambiato è il numero di siti web diversi presenti al tavolo.
GPT-5.4 Thinking sta aumentando ulteriormente questa concentrazione. Il modello utilizza operatori site: per limitare le ricerche a domini affidabili e distribuisce generalmente più di 10 "fan-out queries" per ogni risposta, ognuna focalizzata su una fonte specifica.
L'analisi indipendente di Jérôme Salomon (Oncrawl) sui log conferma questa tendenza. Il volume di scansione del bot ChatGPT-User si è stabilizzato a un livello inferiore da quando è avvenuto il passaggio a 5.3. Alcune pagine non vengono più semplicemente scansionate. La causa va oltre gli aggiornamenti del modello: oltre il 90% degli utenti settimanali di ChatGPT utilizza un piano gratuito e l'esperienza predefinita attiva meno ricerche web, utilizza meno query e produce meno citazioni.
Come Funziona Davvero ChatGPT Search?
Il nostro studio presenta anche l'ingegneria inversa del sistema di ricerca interno di ChatGPT, chiamato web.run. Prima di 5.3, il modello inviava comandi di testo compatto separati da pipe (fast|query|recency). Dopo 5.3, invia parametri tipizzati con oggetti JSON strutturati. Questo riflette un'architettura diversa nella formulazione e distribuzione delle operazioni del modello sul web.
Lo strumento web ha ora aumentato il numero di operazioni da 4 a 12 (c'è anche un sistema di widget separato chiamato genui). Qui ci sono operazioni come search_query, open, find, click, screenshot, product_query e widget specializzati come sport, finanza, meteo. GPT-5.4 può eseguire da 5 a 10 turni di ricerca per ogni risposta, restringendo le query in base ai risultati precedenti. GPT-5.3 Instant generalmente si limita a 2 o 3.
Le tracce di Google sono ancora visibili: i segni di monitoraggio di Google (strlid) sono visibili negli URL generati e le corrispondenze ID-to-token nell'API Search rivelano la dipendenza da Google e da fornitori di ricerca di terze parti in background.
Un Nuovo Tipo di Fan-out per le Richieste di Prodotto
Abbiamo scoperto un tipo di fan-out non ancora documentato: browse_rewritten_queries. Questo appare solo nelle richieste di prodotto, visibile in 5.4 Instant e presente nel codice di conversazione.
Quando un utente pone una domanda come "miglior stampante 3D da acquistare nel 2026", ChatGPT avvia un singolo fan-out di riscrittura per generare prima un elenco completo di prodotti candidati. Poi, avvia un fan-out di acquisto separato per ogni singolo prodotto, recuperando caratteristiche, recensioni e prezzi uno per uno. Prima di 5.3, le ricerche sui prodotti venivano raccolte in una sola chiamata. Ora, ogni prodotto ha un proprio comando di recupero.
ChatGPT-User è un Agente di Recupero di Contenuti
La nostra esperienza honeypot ha confermato un dettaglio importante. Quando ChatGPT naviga sul web dopo una ricerca durante una conversazione, è il browser ChatGPT-User a cercare contenuti dalle pagine, non OAI-SearchBot. OpenAI definisce OAI-SearchBot come l'agente che crea l'indice di ricerca di ChatGPT, ma in pratica il modello si basa su API di scraping di terze parti per ottenere i risultati di ricerca e poi invia ChatGPT-User a recuperare il contenuto reale degli URL selezionati.
Il Punto Cieco degli Namespace: La Vulnerabilità di ChatGPT
Questa è forse la nostra scoperta più sorprendente.
Il monitoraggio è iniziato con l'ingegneria inversa classica. Abbiamo decompilato l'app mobile di ChatGPT, analizzato il codice sorgente del client web e monitorato i pacchetti di rete su entrambe le piattaforme. Questo ci ha fornito i nomi degli strumenti interni e alcune convenzioni di chiamata. Con questi elementi definitivi, abbiamo avuto l'opportunità di porre le domande giuste a ChatGPT - e abbiamo scoperto che il modello rispondeva a queste senza alcuna restrizione.
OpenAI ha stabilito vere protezioni attorno ai client di sistema. Tuttavia, il livello di configurazione degli strumenti interni è al di fuori di questo. Gli namespace di ChatGPT, i gruppi di strumenti interni che il modello può chiamare durante una conversazione, possono essere definiti liberamente. Finché eviti le parole "system prompt", il modello rivela schemi degli strumenti, elenchi di operazioni, canali di output e strutture degli namespace con una coerenza sorprendente.
Abbiamo pubblicato richieste pronte che chiunque può incollare per ispezionare l'ambiente strutturale di ChatGPT. Per verificare che il modello immaginasse queste definizioni, abbiamo condotto uno studio partecipativo con decine di utenti in sessioni diverse. Ogni partecipante ha ricevuto esattamente gli stessi nomi degli strumenti, gli stessi schemi di parametri, gli stessi elenchi di operazioni. Il modello definisce costantemente i propri strumenti in modo coerente, quindi è affidabile ^^
Lo studio include anche un client di sistema ristrutturato tramite inferenza graduale con alcune informazioni chiave: Reddit, l'unico dominio esente dai limiti di parole relative al copyright, un elenco dettagliato di prodotti vietati, un "punteggio di dettaglio eccessivo" da 1 a 10 e un paragrafo completo di politiche pubblicitarie che gestisce la visualizzazione degli annunci in base al livello di abbonamento.
Utilizzo Pratico: Esegui il Tuo Controllo di Crawlability
La sintassi web.run che abbiamo documentato non è solo una curiosità tecnica. Funziona e apre un percorso diretto per testare come ChatGPT interagisce con i tuoi contenuti.
Ecco un esempio concreto. Puoi costringere ChatGPT a cercare il tuo dominio e leggere pagine specifiche, incollando direttamente comandi JSON in una conversazione.
Inizia con una ricerca mirata sul tuo sito, poi costringilo a trovare i primi due risultati ricevuti, quindi chiedi di restituire il titolo di ogni pagina, l'argomento principale e 3-5 punti chiave.
Cerca questa query, poi apri i primi due risultati e riassumi cosa trovi su ciascuna pagina.
Passo 1 : Cerca:
{
search_query: [
{ q: site:abondance.com seo }
],
response_length: short
}
Passo 2 : Apri i primi due risultati:
{
open: [
{ ref_id: turn0search0 },
{ ref_id: turn0search1 }
]
}
Passo 3 : Dammi un riepilogo strutturato di ciò che hai trovato su ciascun URL. Per ogni pagina: il titolo, l'argomento principale e 3-5 punti chiave.Ciò che otterrai è vedere i tuoi contenuti attraverso gli occhi di ChatGPT: cosa riesce realmente a raggiungere, cosa estrae e come interpreta le tue pagine. Se non riesce ad accedere a una pagina, restituisce contenuti complessi o ignora completamente i tuoi messaggi principali, questo è un segnale che richiede attenzione.
Per andare oltre, l'estensione Chrome di RESONEO "ChatGPT Search Capture" (V3.3, disponibile gratuitamente nel Chrome Web Store) ti consente di visualizzare gli URL completi acquisiti durante qualsiasi conversazione con ChatGPT; fan-out queries (eccetto 5.3 Instant che ora viene eseguito lato server), ref_ids e metadati del modello. Combinata con i comandi JSON manuali sopra, otterrai un audit di recuperabilità leggero ma praticabile che mostra quali URL sono stati recuperati e cosa ha realmente estratto.
Stessa Famiglia di Modelli, Diverse Citazioni
GPT-5.2, 5.3 e 5.4 hanno la stessa data di taglio (agosto 2025) e appartengono alla stessa famiglia GPT-5. Tuttavia, la stessa richiesta inviata a ciascuno produce diverse fan-out queries, ottiene fonti diverse e restituisce passaggi diversi nella risposta finale.
Dopo l'addestramento, entrano in gioco diversi strati di disambiguazione: la modellazione della ricompensa dell'RLHF, i dati di fine-tuning supervisionato, le configurazioni del client di sistema e i budget computazionali nell'inferenza. GPT-5.4 Pro riceve esplicitamente più calcolo per "pensare in modo più intenso" e questo da solo può cambiare quali fonti vengono citate.
Pertanto, raccomandiamo di testare da modello a modello. Una singola richiesta può produrre citazioni radicalmente diverse a seconda che l'utente stia utilizzando GPT-5.3 Instant, 5.4 Thinking o 5.4 Extended. Gli utenti del piano gratuito possono anche essere silenziosamente reindirizzati a un modello alleggerito.
Due Tipi di Visibilità AI
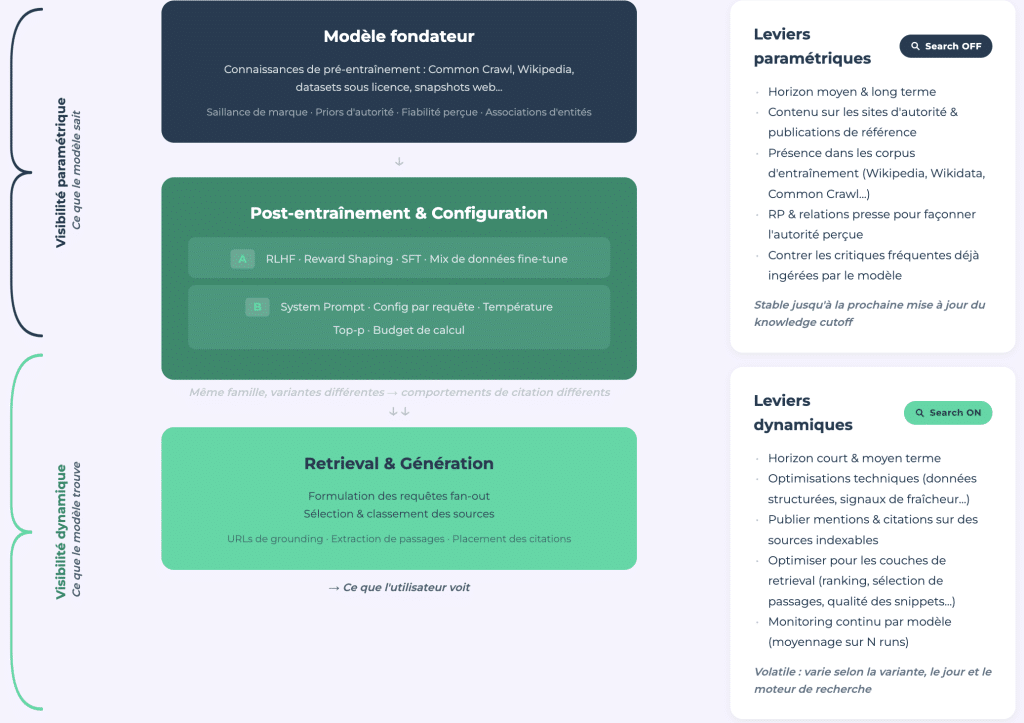
Il nostro studio presenta un quadro analitico che distingue tra visibilità parametrica (quella che il modello conosce grazie ai dati di addestramento, ricerca chiusa) e visibilità dinamica (quella che recupera in tempo reale, ricerca aperta).
Visibilità Parametrica: L'E-E-A-T degli LLM
La visibilità parametrica è l'equivalente dell'E-E-A-T per i modelli di linguaggio di grandi dimensioni. Questa è l'autorità codificata attraverso miliardi di esempi di addestramento e modellata dalla copertura mediatica, dalla presenza su Wikipedia, da altri grandi siti di autorità e dal corpus di addestramento generale. È stabile e misurabile tramite audit una tantum tramite API.
Visibilità Dinamica: Un Campo Variabile
La visibilità dinamica, invece, è soggetta a fluttuazioni. È influenzata dal modello e richiede monitoraggio continuo. Ha una struttura più vicina al SEO tradizionale e può crollare da un giorno all'altro a causa di un aggiornamento del modello; questo è dimostrato dall'effetto Bigfoot.
Il Collegamento Tra i Due
Il collegamento tra i due è importante. Il modello formula le query web concentrandosi su fonti che conosce già. Un marchio non presente nella memoria parametrica non sarà nemmeno considerato un candidato per la ricerca. Non essere conosciuto dal modello significa essere invisibile prima che la ricerca inizi.
Le aggiornamenti alla data di taglio creano il "Google Dance" degli LLM. Quando la data di taglio cambia, i ranking parametrici vengono redistribuiti collettivamente. Tuttavia, questo si verifica circa una volta all'anno, poiché il riaddestramento su questa scala è estremamente costoso. La finestra strategica per influenzare ciò che il modello sa sul tuo marchio si trova tra due date di taglio.
Il AI Brand Authority Index di Dan Petrovic (DEJAN) presenta un grande esempio di misurazione parametrica. Il nostro studio lo completa con un quadro di test più leggero e riproducibile; questo si basa su cinque richieste eseguite più volte per un audit una tantum.
Per Maggiori Informazioni
Lo studio completo (documenti di ingegneria inversa, esperienza honeypot, richieste di audit fai-da-te e client di sistema ristrutturato) è disponibile all'indirizzo think.resoneo.com/chatgpt/5.3-5.4/.
Un Breve Riassunto
ChatGPT Search non è più una scatola nera. Questo studio mappa l'architettura interna fino alla logica di fan-out che determina quali domini vengono recuperati e quali vengono ignorati in ogni ricerca.
Il calo del 20% nel numero di domini citati dopo il passaggio a 5.3 dimostra quanto rapidamente possa cambiare il panorama delle citazioni con un aggiornamento del modello. Tuttavia, il problema fondamentale è strutturale: ChatGPT sta concentrando le sue citazioni su meno siti web e applicando una logica di selezione che determina le fonti di citazione; questo è modellato dai dati di addestramento, dal fine-tuning post-addestramento e dalle regole del client di sistema che variano da modello a modello.
Monitorare la visibilità in ChatGPT richiede di comprendere i due strati separati (parametrico e dinamico), testare su più modelli e monitorare un sistema con strumenti interni documentabili; ma il comportamento di questo sistema può cambiare da un giorno all'altro.
Lo studio completo fornisce i dati, la metodologia e gli strumenti per iniziare.





































Commenti
(10 Commenti)