When OpenAI changed the default model on March 4, the number of referenced websites per response dropped by a fifth and never recovered. However, this decline is only part of the story. We also reverse-engineered ChatGPT's internal browsing tools, conducted a honeypot experience, restructured the system client, and released a new version of our ChatGPT Search Capture plugin.
What Happened?
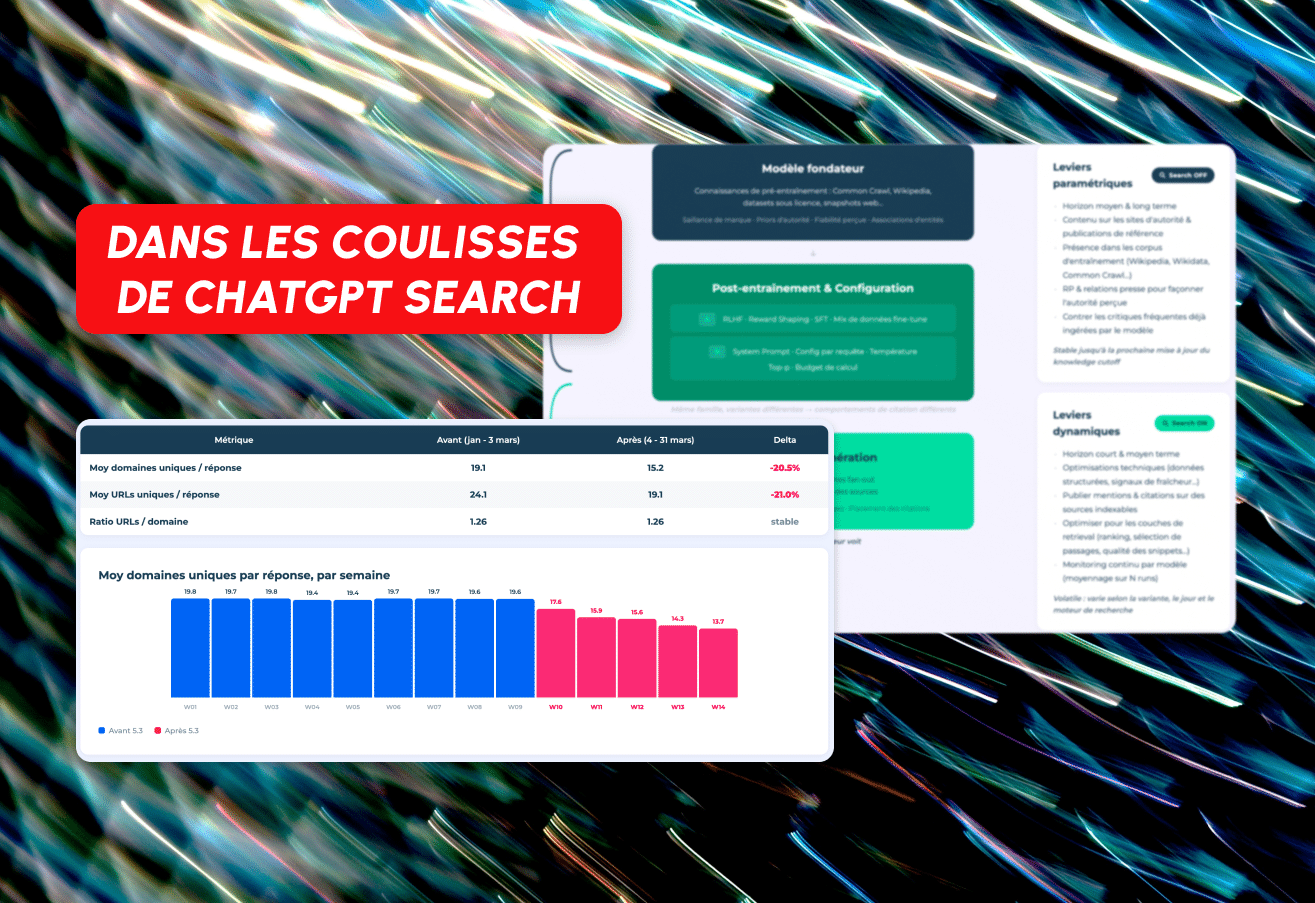
On March 4, 2026, ChatGPT switched its default model from GPT-4o/5.2 to GPT-5.3 Instant. As a result, the average number of unique domains referenced per response fell from 19.1 to 15.2, representing a decrease of more than 20%. The number of unique URLs per response also followed the same path, declining from 24.1 to 19.1.
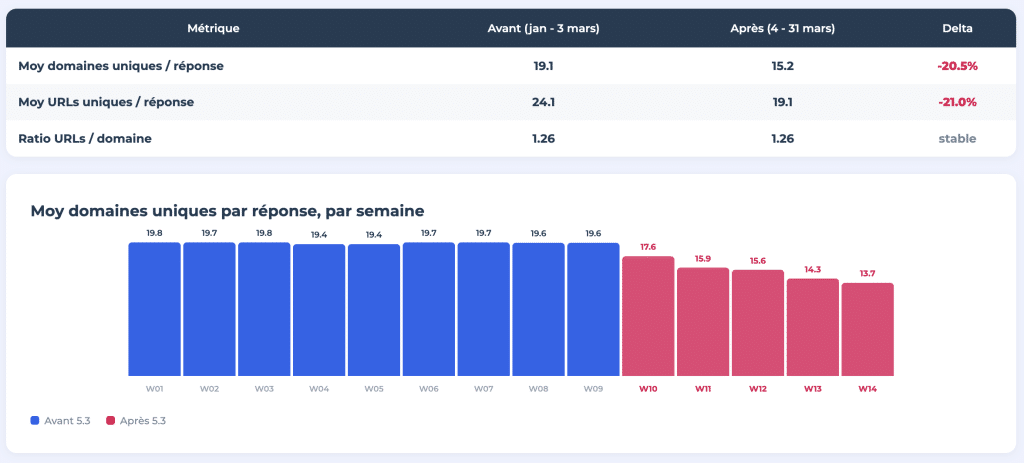
For 14 weeks, we monitored 400 prompts daily, relying on tracking data provided by Meteoria. All results were published as an eight-part interactive study at think.resoneo.com/chatgpt/5.3-5.4/.
Why Is It Important?
ChatGPT has 900 million active users per week. The citation area within each response has not changed, but fewer websites are sharing this space. The same pie, but with fewer slices. This likely reflects a structural shift towards sources with higher authority, but it also means fewer winners overall. Sites that cannot make the cut are losing a visibility area that was previously accessible.
The Bigfoot Effect
We named this phenomenon after the "Bigfoot update" defined by Dr. Pete (from Moz) in 2013; at that time, Google allowed a single domain to sometimes occupy the entire first page...
ChatGPT now takes up less space per response, but the URL per domain ratio has remained stable at 1.26. The scanning depth per domain has not changed. What has changed is the number of different websites at the table.
GPT-5.4 Thinking further increases this concentration. The model uses site: operators to restrict searches to trusted domains and typically distributes more than 10 "fan-out queries" per response, each focusing on a specific source.
Jérôme Salomon's (Oncrawl) independent analysis of logs confirms this trend. The crawling volume of the ChatGPT-User bot has stabilized at a lower level since the transition to 5.3. Some pages are simply no longer being crawled. The reason goes beyond model updates: more than 90% of ChatGPT's weekly users are on a free plan, and the default experience triggers fewer web searches, uses fewer queries, and generates fewer citations.
How Does ChatGPT Search Really Work?
Our study also presents the reverse engineering of ChatGPT's internal search system, called web.run. Before 5.3, the model sent compact text commands separated by pipes (fast|query|recency). After 5.3, it sends typed parameters with structured JSON objects. This reflects a different architecture in how the model formulates and distributes its operations on the web.
The web tool has now increased the number of operations from 4 to 12 (there is also genui, a separate widget system). Here, operations such as search_query, open, find, click, screenshot, product_query, as well as specialized widgets for sports, finance, and weather are present. GPT-5.4 can perform 5 to 10 research rounds per response, narrowing its queries based on previous results. GPT-5.3 Instant typically settles for 2 or 3.
Google traces are still visible: Google tracking markers (strlid) are visible in the generated URLs, and ID-to-token matches in SearchAPI reveal the dependency on Google and third-party search providers in the background.
A New Type of Fan-out for Product Queries
We discovered an undocumented type of fan-out: browse_rewritten_queries. This is only visible in product queries in 5.4 Instant and is present in the conversation code.
When a user asks a question like "the best 3D printer to buy in 2026," ChatGPT first initiates a single rewriting fan-out to generate a complete list of candidate products. Then, it initiates a separate shopping fan-out for each individual product, retrieving specifications, reviews, and prices one by one. Before 5.3, product searches were aggregated in a single call. Now, each product has its own retrieval command.
ChatGPT-User Is the Content Retrieval Agent
Our honeypot experience confirmed an important detail. When ChatGPT browses the web after a search during a conversation, it is the ChatGPT-User browser that searches for content from pages, not the OAI-SearchBot. OpenAI defines the OAI-SearchBot as the agent that creates ChatGPT's search index, but in practice, the model relies on third-party scraping APIs to obtain search results and then sends the ChatGPT-User to retrieve the actual content of the selected URLs.
The Blind Spot of Namespaces: ChatGPT's Vulnerability
This may be our most surprising discovery.
Tracking began with classic reverse engineering. We decompiled the ChatGPT mobile app, dissected the source code of the web client, and monitored network packets on both platforms. This gave us the names of internal tools and some calling conventions. With these precise elements, we had the opportunity to ask ChatGPT the right questions - and discovered that the model answered them without any restrictions.
OpenAI has established real protections around system clients. However, the configuration layer of internal tools is outside of this. ChatGPT's namespaces, groups of internal tools that the model can call during a conversation, can be freely defined. As long as you avoid the words "system prompt," the model reveals tool schemas, operation lists, output channels, and namespace structures with remarkable consistency.
We published ready-made prompts that anyone can paste to audit ChatGPT's structural environment. To verify that the model imagines these definitions, we conducted a participatory study with dozens of users in different sessions. Each participant received exactly the same tool names, the same parameter schemas, and the same operation lists. The model consistently defines its own tools, making it reliable.
The study also includes a restructured system client through gradual inference along with several important pieces of information: Reddit, the only domain exempt from copyright word limits, a detailed list of banned products, an "excess detail score" from 1 to 10, and a complete advertising policy paragraph governing the display of ads based on subscription level.
Practical Use: Conduct Your Own Crawlability Audit
The documented web.run syntax is not just a technical curiosity. It works and opens a direct way to test how ChatGPT interacts with your content.
Here’s a concrete example. You can force ChatGPT to search your domain and read specific pages by pasting JSON commands directly into a conversation.
First, initiate a targeted search on your site, then force it to find the first two results, and then ask it to return the title, main topic, and 3-5 key points of each page.
Search for this query, then open the first two results and summarize what you find on each page.
Step 1 : Search:
{
search_query: [
{ q: site:abondance.com seo }
],
response_length: short
}
Step 2 : Open the first two results:
{
open: [
{ ref_id: turn0search0 },
{ ref_id: turn0search1 }
]
}
Step 3 : Give me a structured recap of what you found on each URL. For each page: the title, the main topic, and 3-5 key points.What you’ll get is a view of your content from ChatGPT's perspective: what it can actually access, what it extracts, and how it interprets your pages. If it cannot access a page, returns complex content, or completely ignores your main messages, this is a signal that action needs to be taken.
To go further, RESONEO's Chrome extension "ChatGPT Search Capture" (V3.3, available for free on the Chrome Web Store) allows you to visualize the exact URLs captured during any ChatGPT conversation; fan-out queries (except for 5.3 Instant, which now runs server-side), ref_ids, and the model's metadata. When combined with the manual JSON commands above, you get a lightweight yet actionable crawlability audit that shows which URLs were retrieved and what was actually extracted.
Same Model Family, Different Citations
GPT-5.2, 5.3, and 5.4 share the same cutoff date (August 2025) and belong to the same GPT-5 family. However, the same prompt sent to each produces different fan-out queries, retrieves different sources, and returns different passages in the final response.
After pre-training, several layers of divergence come into play: RLHF's reward shaping, supervised fine-tuning data, configurations of the system client, and computational budgets in inference. GPT-5.4 Pro clearly receives more computation for "thinking more intensively," which can alone change which sources are cited.
Therefore, we recommend testing from model to model. A single prompt can produce radically different citations depending on whether the user is on GPT-5.3 Instant, 5.4 Thinking, or 5.4 Extended. Free plan users may also be quietly directed to a slightly reduced model.
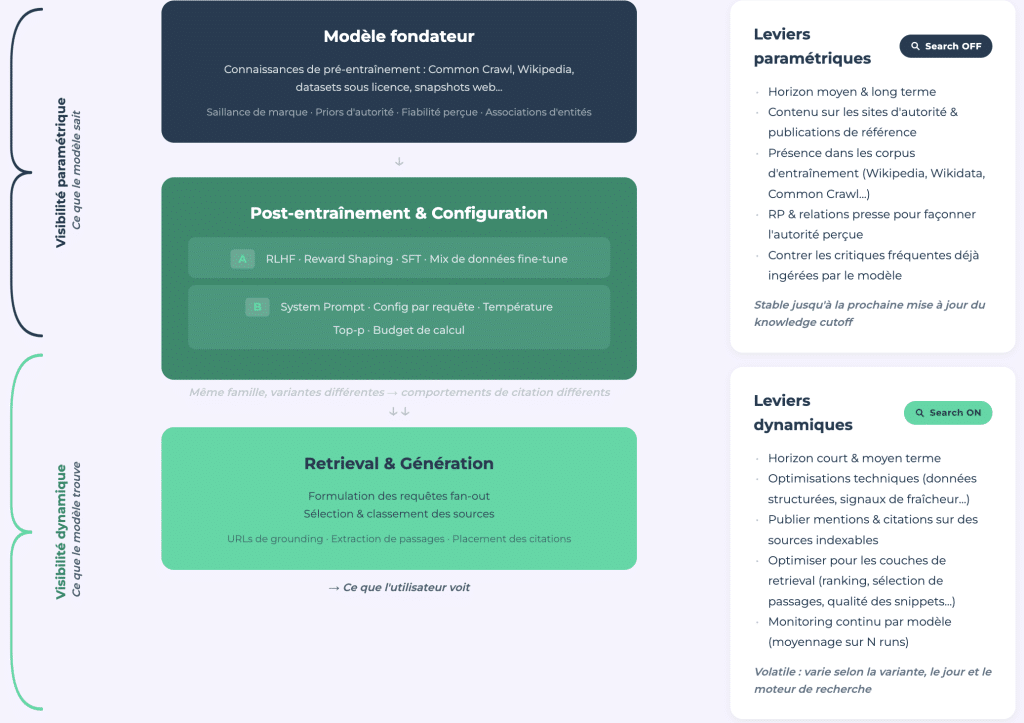
Two Types of AI Visibility
Our study presents an analytical framework that distinguishes between parametric visibility (what the model knows through its training data, search closed) and dynamically visibility (what it retrieves in real-time, search open).
Parametric Visibility: The E-E-A-T of LLMs
Parametric visibility is the equivalent of E-E-A-T for large language models. This is authority encoded through billions of training examples and shaped by media coverage, presence on Wikipedia, other major authority sites, and the general training corpus. It is stable and measurable through one-time audits via API.
Dynamically Visibility: A Variable Field
Dynamically visibility, on the other hand, is volatile. It is influenced by the model and requires continuous monitoring. It has a structure closer to traditional SEO and can collapse overnight with a model update; this is demonstrated by the Bigfoot effect.
The Connection Between the Two
The connection between the two is important. The model formulates web queries by focusing on sources it already knows. A brand not present in parametric memory will not even be considered a candidate for search. Being unknown to the model means being invisible before the search even starts.
Updates at the cutoff date create the "Google Dance" of LLMs. When the cutoff date changes, parametric rankings are collectively redistributed. However, this occurs approximately once a year, as retraining at this scale is extremely costly. The strategic window to influence what the model knows about your brand lies between two cutoff dates.
Dan Petrovic's (DEJAN) AI Brand Authority Index presents a large-scale example of parametric measurement. Our study complements this with a lighter and reproducible testing framework; this is based on five prompts executed several times for a one-time audit.
For More Information
The full study (reverse engineering documents, honeypot experience, DIY audit prompts, and restructured system client) is available at think.resoneo.com/chatgpt/5.3-5.4/.
A Brief Summary
ChatGPT Search is no longer a black box. This study maps its internal architecture, from the fan-out logic that determines which domains are retrieved and which are ignored for each search, to the web.run tool that drives every search.
The 20% drop in the number of referenced domains after the transition to 5.3 shows how quickly the citation landscape can change with a model update. However, the underlying issue is structural: ChatGPT is concentrating its citations on fewer websites and applying a selection logic that determines citation sources; this is shaped by training data, post-training fine-tuning, and system client rules that vary from model to model.
Tracking visibility in ChatGPT requires understanding two separate layers (parametric and dynamic), testing across multiple models, and monitoring a system with documentable internal tools; however, the behavior of this system can change overnight.
The full study provides the data, methodology, and tools to get you started.






































Comments
(10 Comments)