A OpenAI, ao mudar o modelo padrão em 4 de março, viu o número de sites referenciados por resposta cair em um quinto, e nunca mais se recuperou. No entanto, essa queda é apenas uma parte da história. Também realizamos a engenharia reversa das ferramentas internas de busca do ChatGPT, realizamos uma experiência de honeypot, reconfiguramos o cliente do sistema e lançamos uma nova versão do nosso plugin ChatGPT Search Capture.
O Que Aconteceu?
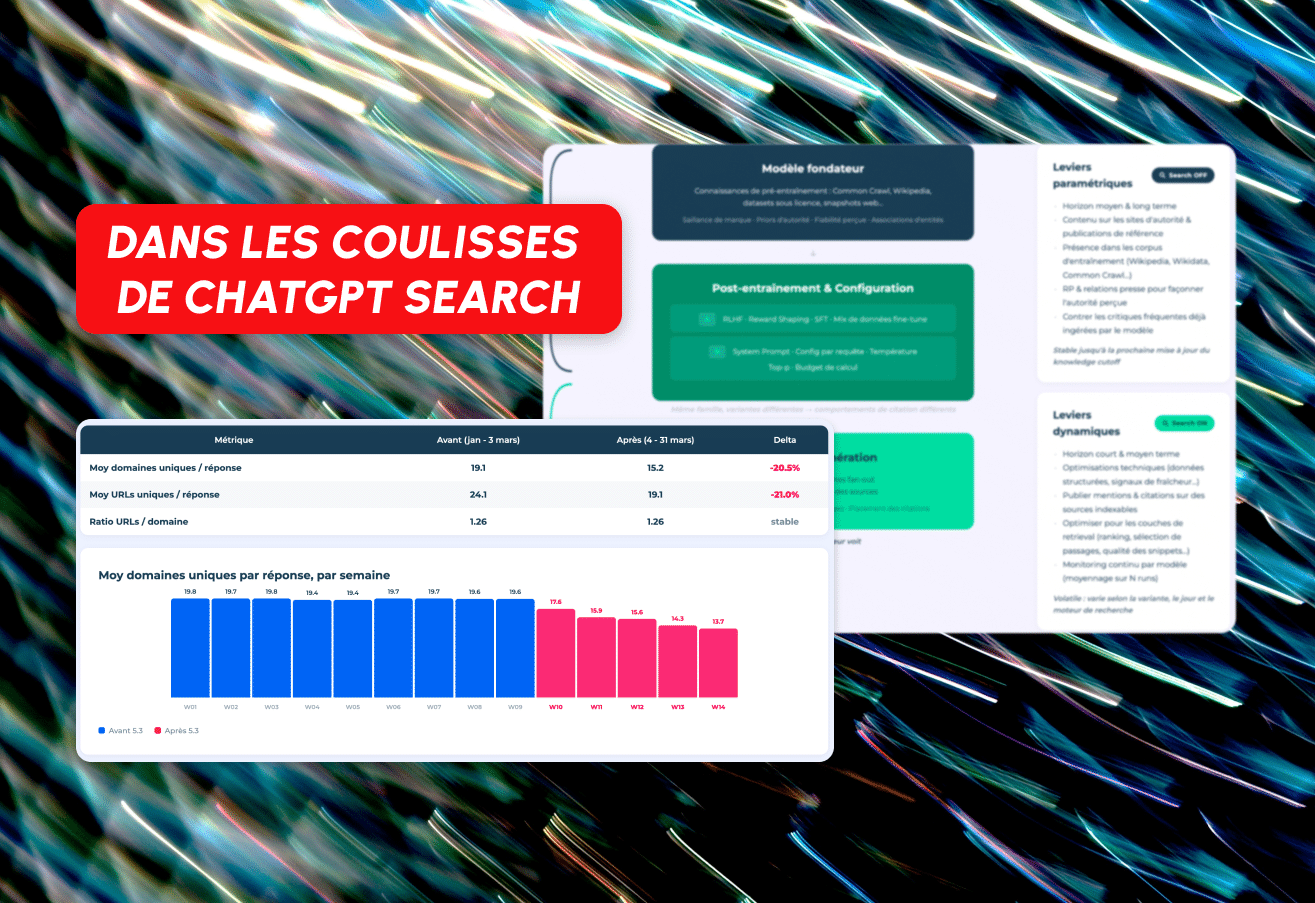
Em 4 de março de 2026, o ChatGPT mudou seu modelo padrão de GPT-4o/5.2 para GPT-5.3 Instant. Como resultado, o número médio de domínios únicos referenciados por resposta caiu de 19,1 para 15,2, o que representa uma redução de mais de 20%. O número de URLs únicos por resposta também seguiu o mesmo caminho, caindo de 24,1 para 19,1.
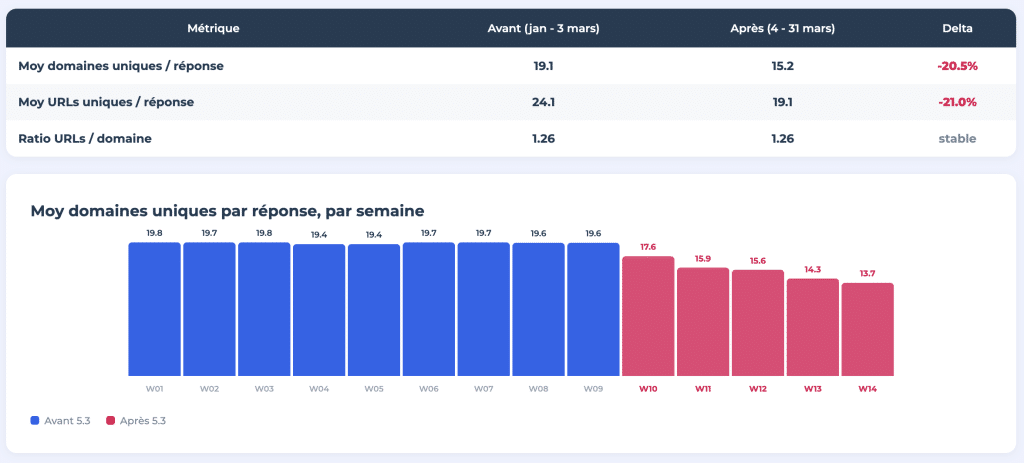
Durante 14 semanas, monitoramos 400 solicitações diárias, baseando-nos nos dados de monitoramento fornecidos pela Meteoria. Todos os resultados foram publicados como um estudo interativo de oito partes em think.resoneo.com/chatgpt/5.3-5.4/.
Por Que É Importante?
O ChatGPT possui 900 milhões de usuários ativos por semana. O espaço de referência dentro de cada resposta não mudou, mas menos sites estão compartilhando esse espaço. O mesmo bolo, mas com menos fatias. Isso provavelmente reflete uma mudança estrutural em direção a fontes com maior autoridade, mas também significa, de forma geral, menos vencedores. Os sites que não conseguem passar estão perdendo um espaço de visibilidade que antes era acessível.
Efeito Bigfoot
Nomeamos esse fenômeno em referência à "atualização Bigfoot" definida pelo Dr. Pete (da Moz) em 2013; naquela época, o Google permitia que um único domínio cobrisse toda a primeira página...
O ChatGPT agora recebe menos espaço por resposta, mas a proporção de URLs por domínio permaneceu fixa em 1,26. A profundidade de busca por domínio não mudou. O que mudou é o número de sites diferentes na mesa.
O GPT-5.4 Thinking está aumentando ainda mais essa concentração. O modelo usa operadores site: para restringir buscas a domínios confiáveis e geralmente distribui mais de 10 "consultas de fan-out" por resposta, cada uma focando em uma fonte específica.
A análise independente de Jérôme Salomon (Oncrawl) sobre logs confirma essa tendência. O volume de rastreamento do bot ChatGPT-User estabilizou em um nível mais baixo desde a transição para 5.3. Algumas páginas agora simplesmente não estão sendo rastreadas. A razão vai além das atualizações do modelo: mais de 90% dos usuários semanais do ChatGPT estão usando um plano gratuito, e a experiência padrão desencadeia menos buscas na web, usa menos consultas e gera menos referências.
Como o ChatGPT Search Realmente Funciona?
Nossa pesquisa também apresenta a engenharia reversa do sistema de busca interno do ChatGPT, denominado web.run. Antes de 5.3, o modelo enviava comandos de texto compactos separados por pipes (fast|query|recency). Após 5.3, ele envia parâmetros tipados com objetos JSON estruturados. Isso reflete uma arquitetura diferente na forma como o modelo formula e distribui operações na web.
A ferramenta web agora aumentou o número de operações de 4 para 12 (também há um sistema de widget separado chamado genui). Aqui, encontramos operações como search_query, open, find, click, screenshot, product_query, além de widgets específicos como esportes, finanças e clima. O GPT-5.4 pode realizar de 5 a 10 rodadas de pesquisa por resposta, restringindo suas consultas com base nos resultados anteriores. O GPT-5.3 Instant geralmente se contenta com 2 ou 3.
Os rastros do Google ainda estão visíveis: marcas de rastreamento do Google (strlid) são visíveis nas URLs geradas, e as correspondências ID-to-token na SearchAPI revelam a dependência do Google e de provedores de busca de terceiros nos bastidores.
Um Novo Tipo de Fan-out para Consultas de Produtos
Descobrimos um tipo de fan-out ainda não documentado: browse_rewritten_queries. Isso aparece apenas em consultas de produtos, visível no 5.4 Instant e presente no código de conversa.
Quando um usuário faz uma pergunta como "melhor impressora 3D para comprar em 2026", o ChatGPT inicia um único fan-out de reescrita para gerar uma lista completa de produtos candidatos. Em seguida, inicia um fan-out de compras separado para cada produto individual, obtendo características, comentários e preços um a um. Antes de 5.3, as pesquisas de produtos eram agrupadas em uma única chamada. Agora, cada produto tem seu próprio comando de recuperação.
ChatGPT-User é um Agente de Recuperação de Conteúdo
Nossa experiência de honeypot confirmou um detalhe importante. Quando o ChatGPT navega na web após uma busca durante uma conversa, ele é um navegador ChatGPT-User, não um OAI-SearchBot. A OpenAI define o OAI-SearchBot como o agente que cria o índice de busca do ChatGPT, mas na prática, o modelo depende de APIs de scraping de terceiros para obter resultados de busca e, em seguida, envia o ChatGPT-User para recuperar o conteúdo real das URLs selecionadas.
Ponto Cego dos Namespaces: A Vulnerabilidade do ChatGPT
Essa talvez seja a nossa descoberta mais surpreendente.
O monitoramento começou com engenharia reversa clássica. Descompilamos o aplicativo móvel do ChatGPT, analisamos o código-fonte do cliente web e monitoramos pacotes de rede em ambas as plataformas. Isso nos deu os nomes das ferramentas internas e algumas convenções de chamadas. Com esses elementos específicos, tivemos a oportunidade de fazer as perguntas certas ao ChatGPT - e descobrimos que o modelo respondia a elas sem restrições.
A OpenAI estabeleceu proteções reais em torno dos clientes do sistema. No entanto, a camada de configuração das ferramentas internas está fora disso. Os namespaces do ChatGPT, grupos de ferramentas internas que o modelo pode chamar durante uma conversa, podem ser definidos livremente. Desde que você evite as palavras do "prompt do sistema", o modelo revela esquemas de ferramentas, listas de operações, canais de saída e estruturas de namespace com uma consistência impressionante.
Publicamos prompts prontos que qualquer um pode colar para auditar o ambiente estrutural do ChatGPT. Para validar que o modelo imagina essas definições, realizamos um estudo participativo com dezenas de usuários em diferentes sessões. Cada participante recebeu exatamente os mesmos nomes de ferramentas, os mesmos esquemas de parâmetros e as mesmas listas de operações. O modelo define suas ferramentas de maneira consistentemente confiável, portanto, é seguro ^^
O estudo também inclui um cliente de sistema reestruturado por meio de inferência progressiva com várias informações importantes: Reddit, o único domínio isento de limites de palavras relacionadas a direitos autorais, uma lista detalhada de produtos proibidos, uma "pontuação de detalhe excessivo" de 1 a 10 e um parágrafo completo de política de anúncios que regula a exibição de anúncios com base no nível de assinatura.
Uso Prático: Realize Sua Própria Auditoria de Crawlability
A sintaxe do web.run que documentamos não é apenas uma curiosidade técnica. Ela funciona e abre um caminho direto para testar como o ChatGPT interage com seus conteúdos.
Aqui está um exemplo concreto. Você pode forçar o ChatGPT a buscar seu domínio e ler páginas específicas, colando comandos JSON diretamente em uma conversa.
Primeiro, inicie uma busca direcionada em seu site, depois force-o a encontrar os dois primeiros resultados recebidos, e então peça que ele envie de volta o título de cada página, o tópico principal e 3-5 pontos principais.
Search for this query, then open the first two results and summarize what you find on each page.
Step 1 : Search:
{
search_query: [
{ q: site:abondance.com seo }
],
response_length: short
}
Step 2 : Open the first two results:
{
open: [
{ ref_id: turn0search0 },
{ ref_id: turn0search1 }
]
}
Step 3 : Give me a structured recap of what you found on each URL. For each page: the title, the main topic, and 3-5 key points.O que você obterá é ver seu conteúdo pela ótica do ChatGPT: o que ele realmente consegue acessar, o que extrai e como interpreta suas páginas. Se ele não consegue acessar uma página, retorna um conteúdo complexo ou ignora completamente suas mensagens principais, isso é um sinal de que você deve agir.
Para ir mais longe, a extensão do Chrome da RESONEO "ChatGPT Search Capture" (V3.3, disponível gratuitamente na Chrome Web Store) permite que você visualize as URLs completas capturadas durante qualquer conversa do ChatGPT; consultas de fan-out (exceto 5.3 Instant que agora são executadas do lado do servidor), ref_ids e os metadados do modelo. Quando combinados com os comandos JSON manuais acima, você obtém uma auditoria leve, mas viável, de recuperabilidade que mostra quais URLs foram recuperadas e o que realmente foi extraído.
Mesma Família de Modelos, Diferentes Referências
GPT-5.2, 5.3 e 5.4 têm a mesma data de corte (agosto de 2025) e pertencem à mesma família GPT-5. No entanto, o mesmo prompt enviado a cada um produz diferentes consultas de fan-out, obtém fontes diferentes e retorna passagens diferentes na resposta final.
Após o pré-treinamento, várias camadas de divergência entram em jogo: a modelagem de recompensa do RLHF, os dados de ajuste fino supervisionado, as configurações do cliente do sistema e os orçamentos de computação durante a inferência. O GPT-5.4 Pro recebe claramente mais computação para "pensar de forma mais intensa", e isso por si só pode mudar quais fontes são referenciadas.
Portanto, sugerimos testes de modelo para modelo. Um único prompt pode gerar referências radicalmente diferentes dependendo se o usuário está no GPT-5.3 Instant, 5.4 Thinking ou 5.4 Extended. Usuários de planos gratuitos também podem ser direcionados silenciosamente para um modelo suavizado.
Dois Tipos de Visibilidade de IA
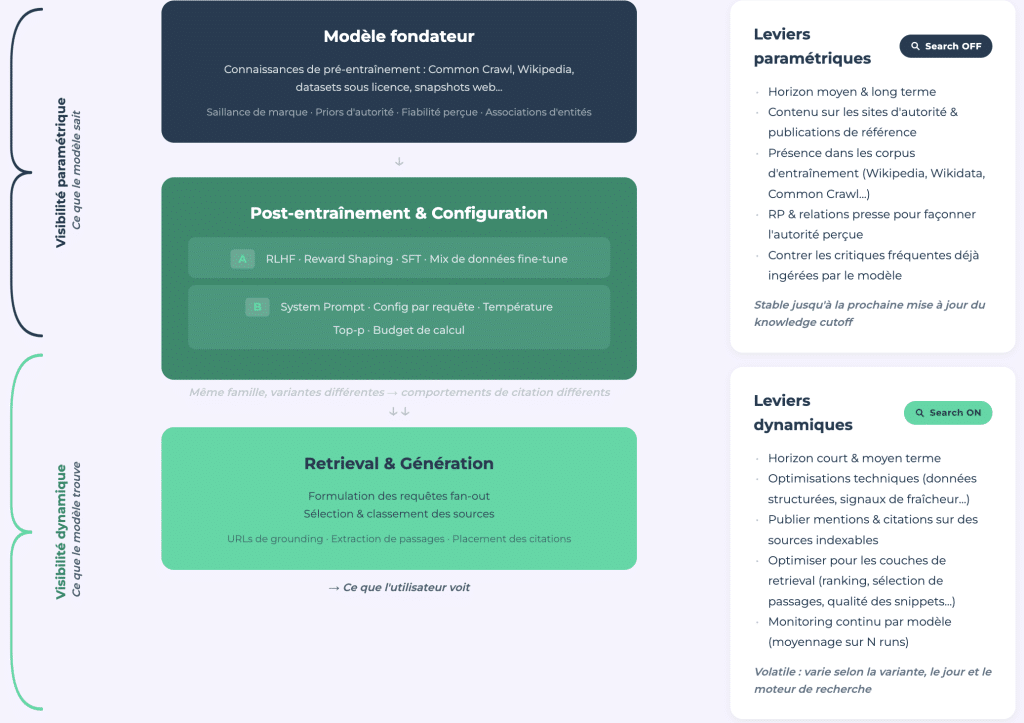
Nossa pesquisa oferece uma estrutura analítica que distingue entre visibilidade paramétrica (o que o modelo sabe devido aos dados de treinamento, busca fechada) e visibilidade dinâmica (o que ele recupera em tempo real, busca aberta).
Visibilidade Paramétrica: E-E-A-T dos LLMs
A visibilidade paramétrica é o equivalente ao E-E-A-T para grandes modelos de linguagem. É a autoridade codificada através de bilhões de exemplos de treinamento e é moldada pela cobertura da mídia, presença na Wikipedia, outros sites de grande autoridade e o corpus de treinamento geral. É estável e pode ser medida com auditorias únicas por meio da API.
Visibilidade Dinâmica: Um Domínio Variável
A visibilidade dinâmica, por sua vez, é volátil. É afetada pelo modelo e requer monitoramento contínuo. Tem uma estrutura mais próxima do SEO tradicional e pode colapsar da noite para o dia com uma atualização de modelo; isso é demonstrado pelo efeito Bigfoot.
A Conexão Entre os Dois
A conexão entre os dois é importante. O modelo formula consultas da web focando em fontes que já conhece. Uma marca que não está na memória paramétrica nem sequer será considerada como candidata para busca. Não ser conhecido pelo modelo significa ser invisível antes mesmo da busca começar.
Atualizações na data de corte criam a "Dança do Google" dos LLMs. Quando a data de corte muda, as classificações paramétricas são redistribuídas coletivamente. No entanto, isso ocorre cerca de uma vez por ano, pois o re-treinamento em tal escala é extremamente custoso. A janela estratégica para influenciar o que o modelo sabe sobre sua marca está entre duas datas de corte.
O Índice de Autoridade de Marca de IA de Dan Petrovic (DEJAN) apresenta um grande exemplo de medição paramétrica em larga escala. Nossa pesquisa complementa isso com uma estrutura de teste mais leve e reproduzível; isso é baseado em cinco prompts executados várias vezes para uma auditoria única.
Para Mais Informações
O estudo completo (documentos de engenharia reversa, experiência de honeypot, prompts de auditoria DIY e cliente de sistema reestruturado) está disponível em think.resoneo.com/chatgpt/5.3-5.4/.
Um Resumo Rápido
A Pesquisa ChatGPT não é mais uma caixa-preta. Este estudo mapeia sua arquitetura interna, desde a lógica de fan-out que determina quais domínios são recuperados e quais são ignorados, até cada busca que ela direciona.
A queda de 20% no número de domínios referenciados após a transição para 5.3 demonstra quão rapidamente a paisagem de referências pode mudar com uma atualização de modelo. No entanto, o problema fundamental é estrutural: o ChatGPT está concentrando suas referências em menos sites e aplicando uma lógica de seleção que determina as fontes de referência; isso é moldado pelos dados de treinamento, ajuste fino pós-treinamento e regras de cliente de sistema que variam de modelo para modelo.
Monitorar a visibilidade no ChatGPT requer entender duas camadas distintas (paramétrica e dinâmica), testar em múltiplos modelos e monitorar um sistema com ferramentas internas documentáveis; no entanto, o comportamento desse sistema pode mudar da noite para o dia.
O estudo completo fornece os dados, a metodologia e as ferramentas para você começar.





































Comentários
(10 Comentários)