OpenAI, al cambiar el modelo por defecto el 4 de marzo, vio caer en un quinto la cantidad de sitios web referenciados por respuesta, y nunca se recuperó. Pero esta caída es solo una parte de la historia. También hemos realizado ingeniería inversa de las herramientas de búsqueda internas de ChatGPT, llevamos a cabo una experiencia de honeypot, reconfiguramos el cliente del sistema y lanzamos una nueva versión de nuestro complemento ChatGPT Search Capture.
¿Qué Sucedió?
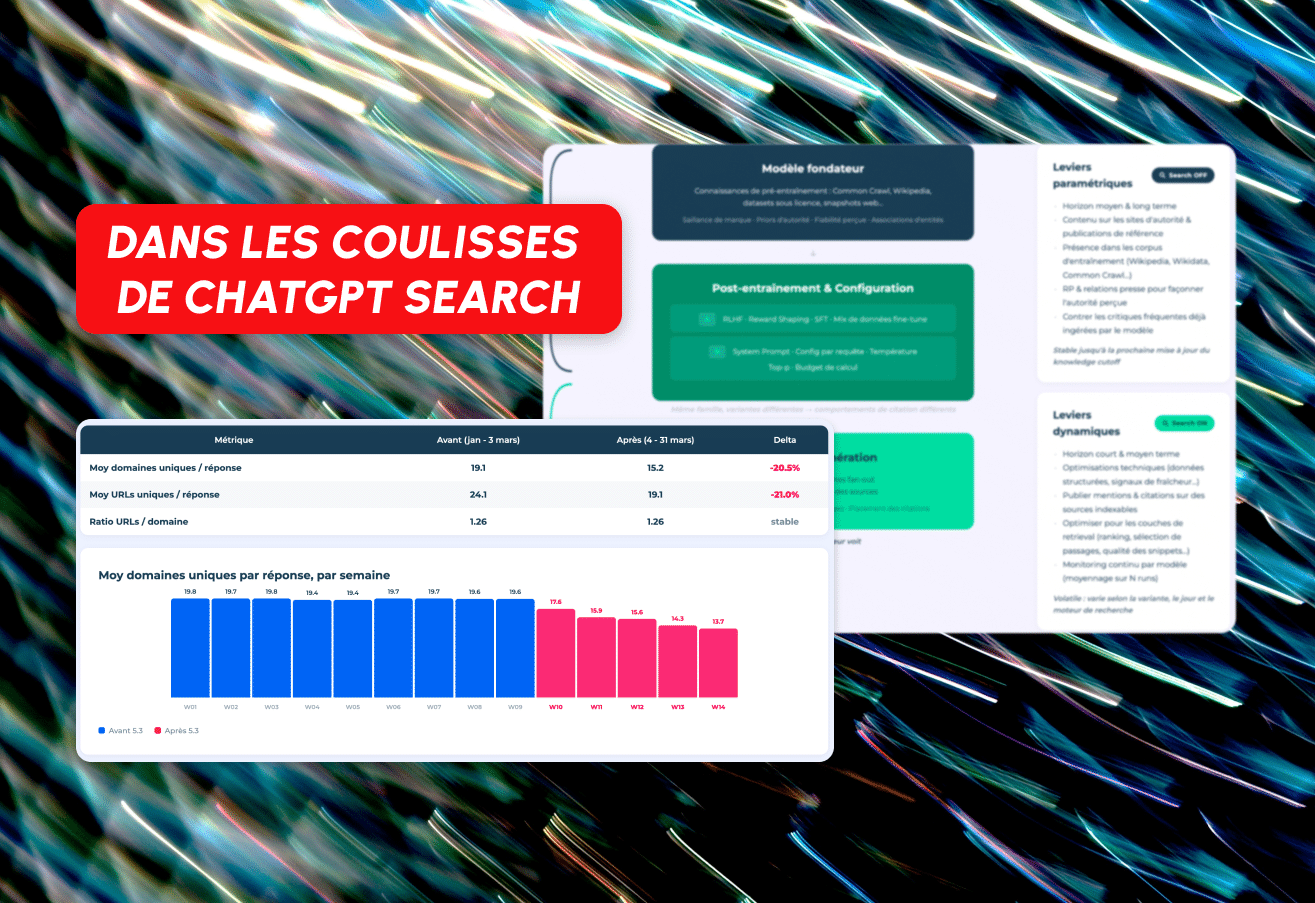
El 4 de marzo de 2026, ChatGPT cambió su modelo por defecto de GPT-4o/5.2 a GPT-5.3 Instant. Como resultado, la cantidad promedio de dominios únicos referenciados por respuesta cayó de 19.1 a 15.2, lo que representa una disminución de más del 20%. La cantidad de URL únicas por respuesta también siguió el mismo camino, disminuyendo de 24.1 a 19.1.
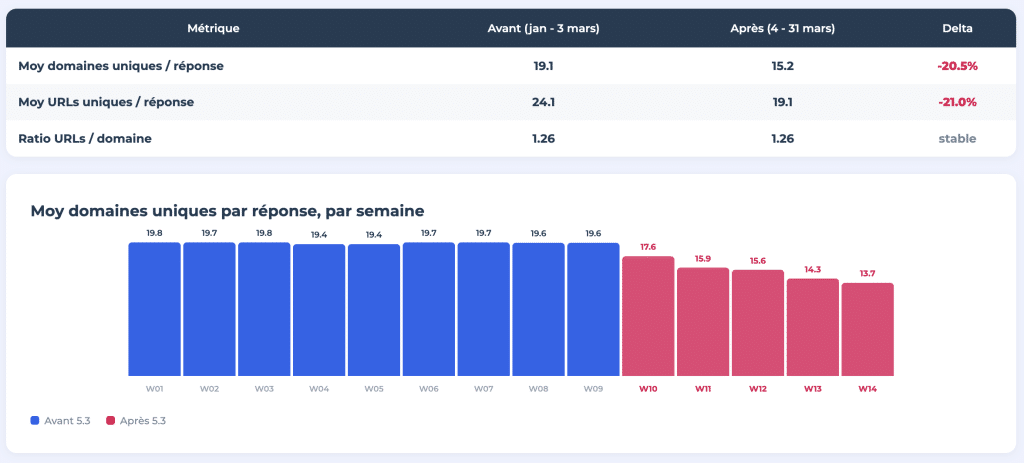
Durante 14 semanas, monitoreamos 400 solicitudes diarias, basándonos en los datos de seguimiento proporcionados por Meteoria. Todos los resultados se publicaron como un estudio interactivo de ocho partes en think.resoneo.com/chatgpt/5.3-5.4/.
¿Por Qué es Importante?
ChatGPT tiene 900 millones de usuarios activos por semana. El área de referencia dentro de cada respuesta no ha cambiado, pero menos sitios web comparten esa área. Es el mismo pastel, pero con menos porciones. Esto refleja probablemente un desplazamiento estructural hacia fuentes de mayor autoridad, pero también significa, en general, menos ganadores. Los sitios que no pueden superar la selección están perdiendo un área de visibilidad que antes era accesible.
Efecto Bigfoot
Nombramos este fenómeno en referencia a la "actualización Bigfoot" definida por el Dr. Pete (de Moz) en 2013; en ese momento, Google permitía que, a veces, un solo dominio cubriera toda la primera página...
ChatGPT ahora recibe menos dominios por respuesta, pero la proporción de URL por dominio se ha mantenido constante en 1.26. La profundidad de búsqueda por dominio no ha cambiado. Lo que ha cambiado es la cantidad de sitios web diferentes en la mesa.
GPT-5.4 Thinking está aumentando aún más esta concentración. El modelo utiliza operadores site: para restringir las búsquedas a dominios confiables y generalmente distribuye más de 10 "consultas de fan-out" por respuesta, cada una centrada en una fuente específica.
El análisis independiente de los registros de Jérôme Salomon (Oncrawl) confirma esta tendencia. El volumen de rastreo del bot ChatGPT-User se ha estabilizado en un nivel más bajo desde la transición a 5.3. Algunas páginas ya no se rastrean simplemente. La razón va más allá de las actualizaciones del modelo: más del 90% de los usuarios semanales de ChatGPT utilizan un plan gratuito, y la experiencia por defecto desencadena menos búsquedas web, utiliza menos consultas y produce menos referencias.
¿Cómo Funciona Realmente ChatGPT Search?
Nuestro estudio también presenta la ingeniería inversa del sistema de búsqueda interno de ChatGPT, denominado web.run. Antes de 5.3, el modelo enviaba comandos de texto compactos separados por pipes (fast|query|recency). Después de 5.3, envía parámetros tipados con objetos JSON estructurados. Esto refleja una arquitectura diferente en la forma en que el modelo formula y distribuye sus operaciones en la web.
La herramienta web ahora ha aumentado el número de operaciones de 4 a 12 (también hay un sistema de widget separado llamado genui). Aquí se encuentran operaciones como search_query, open, find, click, screenshot, product_query y widgets específicos como deportes, finanzas y clima. GPT-5.4 puede realizar de 5 a 10 rondas de investigación por respuesta, afinando sus consultas en función de resultados anteriores. GPT-5.3 Instant generalmente se limita a 2 o 3.
Las huellas de Google todavía son visibles: las marcas de seguimiento de Google (strlid) son visibles en las URL generadas, y las coincidencias ID-to-token en SearchAPI revelan la dependencia de Google y proveedores de búsqueda de terceros en segundo plano.
Un Nuevo Tipo de Fan-out para Consultas de Productos
Descubrimos un tipo de fan-out aún no documentado: browse_rewritten_queries. Esto aparece solo en consultas de productos, en 5.4 Instant, y está presente en el código de conversación.
Cuando un usuario pregunta: "¿Cuál es la mejor impresora 3D para comprar en 2026?", ChatGPT inicia un único fan-out de reescritura para generar primero una lista completa de productos candidatos. Luego, inicia un fan-out de compras separado para cada producto individual, obteniendo características, reseñas y precios uno por uno. Antes de 5.3, las búsquedas de productos se agrupaban en una sola llamada. Ahora, cada producto tiene su propio comando de recuperación.
ChatGPT-User es un Agente de Recuperación de Contenido
Nuestra experiencia de honeypot confirmó un detalle importante. Cuando ChatGPT navega por la web después de una búsqueda durante una conversación, es el navegador ChatGPT-User el que busca contenido en las páginas, no OAI-SearchBot. OpenAI define OAI-SearchBot como el agente que crea el índice de búsqueda de ChatGPT, pero en la práctica, el modelo depende de API de scraping de terceros para obtener resultados de búsqueda, y luego envía a ChatGPT-User para obtener el contenido real de las URL seleccionadas.
Punto Ciego de los Namespaces: La Vulnerabilidad de ChatGPT
Este es quizás nuestro descubrimiento más sorprendente.
El monitoreo comenzó con ingeniería inversa clásica. Descompilamos la aplicación móvil de ChatGPT, desglosamos el código fuente del cliente web y monitoreamos los paquetes de red en ambas plataformas. Esto nos dio los nombres de las herramientas internas y algunas convenciones de llamada. Con estos elementos precisos, tuvimos la oportunidad de hacer las preguntas correctas a ChatGPT, y descubrimos que el modelo respondía a estas sin ninguna restricción.
OpenAI ha establecido protecciones reales alrededor de los clientes del sistema. Sin embargo, la capa de configuración de las herramientas internas está fuera de esto. Los namespaces de ChatGPT, grupos de herramientas internas que el modelo puede invocar durante una conversación, son libremente definibles. Siempre que evites las palabras "system prompt", el modelo revela esquemas de herramientas, listas de operaciones, canales de salida y estructuras de namespaces con una consistencia perfecta.
Hemos publicado prompts listos que cualquiera puede pegar para auditar el entorno estructural de ChatGPT. Para verificar que el modelo imagina estas definiciones, realizamos un estudio participativo con decenas de usuarios en diferentes sesiones. Cada participante recibió exactamente los mismos nombres de herramientas, los mismos esquemas de parámetros, las mismas listas de operaciones. El modelo define constantemente sus propias herramientas de manera consistente, por lo que es confiable ^^
El estudio también incluye un cliente del sistema reconfigurado a través de inferencia escalonada con varios datos importantes: Reddit, el único dominio exento de límites de palabras relacionados con derechos de autor, una lista detallada de productos prohibidos, un "puntaje de detalle excesivo" de 1 a 10 y un párrafo completo de política publicitaria que regula la visualización de anuncios según el nivel de suscripción.
Uso Práctico: Realiza Tu Propia Auditoría de Crawlability
La sintaxis de web.run que documentamos no es solo una curiosidad técnica. Funciona y abre un camino directo para probar cómo interactúa ChatGPT con tu contenido.
Aquí hay un ejemplo concreto. Puedes forzar a ChatGPT a buscar tu dominio y leer páginas específicas, haciendo esto al pegar comandos JSON directamente en una conversación.
Primero, inicia una búsqueda dirigida en tu sitio, luego fuerza a encontrar los primeros dos resultados obtenidos, y luego pídele que devuelva el título de cada página, el tema principal y de 3 a 5 puntos clave.
Search for this query, then open the first two results and summarize what you find on each page.
Step 1 : Search:
{
search_query: [
{ q: site:abondance.com seo }
],
response_length: short
}
Step 2 : Open the first two results:
{
open: [
{ ref_id: turn0search0 },
{ ref_id: turn0search1 }
]
}
Step 3 : Give me a structured recap of what you found on each URL. For each page: the title, the main topic, and 3-5 key points.Lo que obtendrás es ver tu contenido a través de los ojos de ChatGPT: qué puede acceder realmente, qué extrae y cómo interpreta tus páginas. Si no puede acceder a una página, devuelve contenido complejo o ignora completamente tus mensajes clave, eso es una señal de que se debe actuar.
Para ir más allá, la extensión de Chrome de RESONEO "ChatGPT Search Capture" (V3.3, gratuita en Chrome Web Store) te permite visualizar las URL completas capturadas durante cualquier conversación de ChatGPT; consultas de fan-out (excepto 5.3 Instant que ahora se ejecuta del lado del servidor), ref_ids y metadatos del modelo. Combinado con los comandos JSON manuales anteriores, obtendrás una auditoría ligera pero aplicable de la recuperabilidad que muestra qué URL fueron recuperadas y qué realmente extrajo.
Misma Familia de Modelos, Diferentes Referencias
GPT-5.2, 5.3 y 5.4 tienen la misma fecha de corte (agosto de 2025) y pertenecen a la misma familia GPT-5. Sin embargo, la misma solicitud enviada a cada uno produce diferentes consultas de fan-out, obtiene diferentes fuentes y devuelve diferentes pasajes en la respuesta final.
Después del preentrenamiento, varios niveles de separación entran en juego: la modelación de recompensas de RLHF, los datos de ajuste fino supervisado, las configuraciones del cliente del sistema y los presupuestos computacionales en la inferencia. GPT-5.4 Pro recibe claramente más computación para "pensar más intensamente", y eso por sí solo puede cambiar qué fuentes se citan.
Por lo tanto, recomendamos probar de modelo a modelo. Una sola solicitud puede generar referencias radicalmente diferentes dependiendo de si el usuario está en GPT-5.3 Instant, 5.4 Thinking o 5.4 Extended. Los usuarios de planes gratuitos también pueden ser silenciosamente dirigidos a un modelo suavizado.
Dos Tipos de Visibilidad de IA
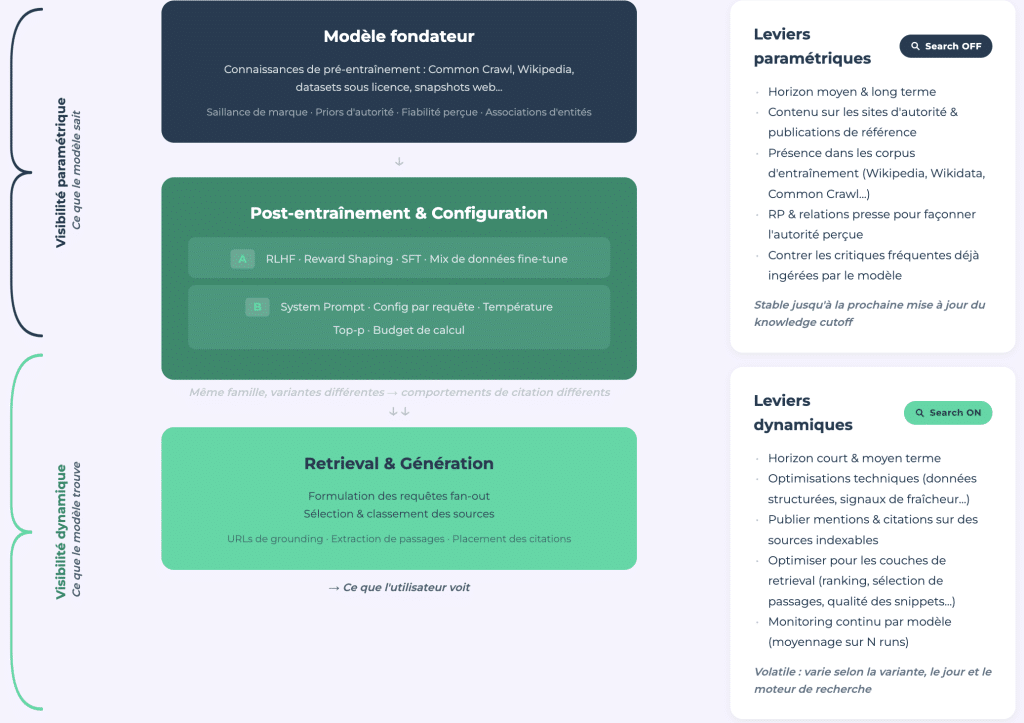
Nuestro estudio presenta un marco analítico que distingue entre visibilidad paramétrica (lo que el modelo sabe gracias a sus datos de entrenamiento, búsqueda cerrada) y visibilidad dinámica (lo que recupera en tiempo real, búsqueda abierta).
Visibilidad Paramétrica: E-E-A-T de los LLMs
La visibilidad paramétrica es el equivalente del E-E-A-T para los grandes modelos de lenguaje. Esta es la autoridad codificada a través de miles de millones de ejemplos de entrenamiento y está moldeada por la cobertura mediática, la presencia en Wikipedia, otros sitios de gran autoridad y el corpus de entrenamiento general. Es medible y estable a través de auditorías únicas a través de API.
Visibilidad Dinámica: Un Dominio Variable
La visibilidad dinámica, por otro lado, es volátil. Se ve afectada por el modelo y requiere monitoreo constante. Tiene una estructura más cercana al SEO tradicional y puede colapsar de la noche a la mañana con una actualización del modelo; esto se ilustra con el efecto Bigfoot.
La Conexión Entre Ambos
La conexión entre ambos es importante. El modelo formula las consultas web enfocándose en fuentes que ya conoce. Una marca que no está en la memoria paramétrica no será considerada siquiera como candidata para la búsqueda. No ser conocido por el modelo significa ser invisible antes de que comience la búsqueda.
Las actualizaciones en la fecha de corte generan el "Baile de Google" de los LLMs. Cuando la fecha de corte cambia, las clasificaciones paramétricas se redistribuyen colectivamente. Sin embargo, esto ocurre aproximadamente una vez al año, ya que volver a entrenar a esta escala es extremadamente costoso. La ventana estratégica para influir en lo que el modelo sabe sobre tu marca se encuentra entre dos fechas de corte.
El Índice de Autoridad de Marca AI de Dan Petrovic (DEJAN) presenta un gran ejemplo de medición paramétrica. Nuestro estudio lo complementa con un marco de prueba más ligero y reproducible; esto se basa en cinco solicitudes ejecutadas varias veces para una auditoría única.
Para Más Información
El estudio completo (documentos de ingeniería inversa, experiencia de honeypot, prompts de auditoría DIY y cliente del sistema reconfigurado) está disponible en think.resoneo.com/chatgpt/5.3-5.4/.
Un Breve Resumen
ChatGPT Search ya no es una caja negra. Este estudio mapea su arquitectura interna, desde la lógica de fan-out que determina qué dominios son recuperados y cuáles son ignorados, hasta el agente web.run que guía cada búsqueda.
La caída del 20% en la cantidad de dominios referenciados después de la transición a 5.3 muestra cuán rápido puede cambiar el panorama de referencias con una actualización del modelo. Sin embargo, el problema subyacente es estructural: ChatGPT está concentrando sus referencias en menos sitios web y aplica una lógica de selección que determina las fuentes de referencia; esto está moldeado por los datos de entrenamiento, el ajuste fino posterior al entrenamiento y las reglas del cliente del sistema que varían de modelo a modelo.
Rastrear la visibilidad en ChatGPT requiere comprender dos capas distintas (paramétrica y dinámica), probar en múltiples modelos y monitorear un sistema con herramientas internas documentables; sin embargo, el comportamiento de este sistema puede cambiar de la noche a la mañana.
El estudio completo proporciona los datos, la metodología y las herramientas para que comiences.








































Comentarios
(10 Comentarios)